Exchange 2010 Database Activation Coordination (DAC)
Exchange 2010 introduced a vast amount of changes to the High Availability model with the addition of the Database Availability Group (DAG). Some features of the DAG are having up to 16 members, automatic database *over to another site as long as you still have quorum, and much more. Exchange also introduced Database Activation Coordination (DAC) mode as an optional addition to the new High Availability model to prevent split brain syndrome from occurring during a site switchover when utilizing a multi-site DAG configuration with at least 3 DAG members and more than one Active Directory Site. DAC is off by default and in Exchange 2010 RTM it should not be enabled for:
- 2 member DAGs
- Non-Multisite DAGs
- Multi-site DAGs that are in the same stretched Active Directory Site
In Exchange 2010 SP1, the following changes are introduced and supported for DAC:
- DAGs that contain 2 or more members
- DAGs that are stretched across a single AD Site
Majority Node Set
Before we understand how DAC works, we really have to understand the Cluster Model that DAGs utilize. Both Exchange 2007 and Exchange 2010 Clusters use Majority Node Set Clustering (MNS). This means that 50% of your votes (server votes and/or 1 file share witness) need to be up and running. The proper formula for this is (n / 2) + 1 where n is the number of DAG nodes within the DAG. With DAGs, if you have an odd number of DAG nodes in the same DAG (Cluster), you have an odd number of votes so you don’t have a witness. If you have an even number of DAGs nodes, you will have a file share witness in case half of your nodes go down, you have a witness who will act as that extra +1 number.
So let’s go through an example. Let’s say we have 3 servers. This means that we need (number of nodes which is 3 / 2) + 1 which equals 2 as you round down since you can’t have half a server/witness. This means that at any given time, we need 2 of our nodes to be online which means we can sustain only 1 (either a server or a file share witness) failure in our DAG. Now let’s say we have 4 servers. This means that we need (number of nodes which is 4 / 2) + 1 which equals 3. This means at any given time, we need 3 of our servers/witness to be online which means we can sustain 2 server failures or 1 server failure and 1 witness failure.
Note: Exchange 2010 DAGs do not use the term Majority Node Set anymore. That term is deprecated and is now called Node Majority or Node Majority with File Share Witness.
Database Activation Coordination (DAC)
In short, DAC mode is enabled when you have at least 3 members to prevent split brain syndrome. It’s as simple as that. Let’s take a look at an example and see how DAC can help. The longer explanation below talks about this specific model.
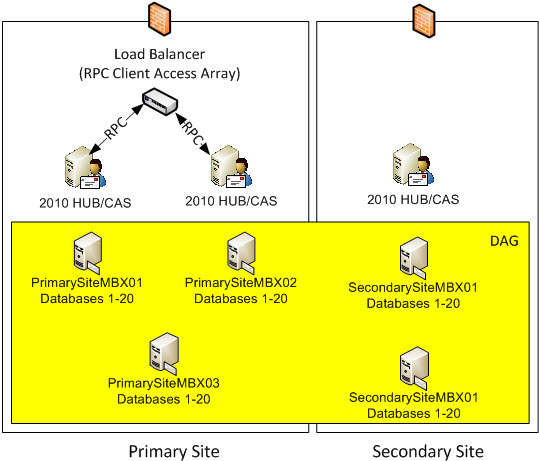
Prevention of Split Brain Syndrome
Short Explanation
When the Primary Site goes offline (or we lose too many servers – refer to Majority Node Set above), the Secondary Site will need to be manually activated should you make the choice that a secondary site activation will be required depending on the magnitude of the failure and how long you anticipate the primary site or servers there will be down. But, when the Primary Site comes back online, the WAN link may be offline. Because the Primary Site’s Exchange Servers don’t necessarily know about the Manual Site Switchover, they will come up thinking they have Quorum since the Primary Site has the majority of the servers and they are still connected to the old FSW. Because of this, they will begin to mount databases since to them, they still have Quorum.
DAC mode will enable the usage of a new protocol, Database Activation Coordination Protocol (DACP). This means that DAG members start up with a special memory bit of 0. They need to contact another DAG node with this special memory bit set to 1. This memory bit will be set to 1 on one of the DAG members in the Secondary Site since that site is hosting active databases. Because the WAN link is down, the Primary Site’s DAG members that just came online won’t be able to contact this DAG member with the special memory bit set to 1. Because of this, they won’t be able to mount databases. The WAN link will have to come back online which means the Primary Site’s DAG members will now be able to contact the DAG member that has the special memory bit set to 1 which will now allow the Primary Site’s DAG Members to be in a state where they are allowed to mount databases.
Longer Explanation
We can see in this example, there are 5 DAG nodes and no FSW as we have an odd number of DAG nodes. Our entire Primary Datacenter Fails (or we lose too many servers – in our case, this would be (5 / 2) + 1 which means 3 of our nodes need to remain operational for the DAG to remain operational), the Secondary Site will need to be manually activated should you make the choice that a secondary site activation will be required depending on the magnitude of the failure and how long you anticipate the primary site or servers there will be down.
Part of the switchover process will have us shrink the DAG by removing the DAG nodes in the Primary Site from the cluster so all that remain of the existing 2 DAG nodes in the Secondary Site. Instructions for shrinking the DAG and doing a manual site actiavtion is locatedhere. Should we decide to proceed with a a manual site switchover , we will provision the FSW in the secondary site during manual site activation to the secondary datacenter. But what happens if the Primary Site’s Exchange Servers come back online? They will think they have majority because the primary site has the majority of the servers and the FSW is located there. Because of this, when they start up, they will begin mounting databases.
Now this is where DAC comes in. Without DAC enabled, the Primary Site’s Exchange Servers would indeed come online, think they have majority, and begin mounting databases and you run into a split-brain syndrome scenario. This is because when power is restored to the datacenter, the servers will usually come up before WAN connectivity is fully restored. The servers cannot communicate with each other between the sites to see that the active databases are already mounted, and because of that, the Primary Exchange Servers will see they have majority since the majority of your servers and your FSW should be in the Primary Site, and mount the databases.
If the servers were allowed to mount databases, and you ran into a split-brain scenario, something called Database Divergence would occur. Database Divergence is where the databases in the primary site would become different from the secondary site causing the need for a reseed from the authority database which would cause some database loss from the new database that went into the diverged database due to split-brain from occurring.
The way DAC works, is that all servers have a new protocol known as Database Activation Coordination Protocol (DACP). One of the DAG Nodes will always have a special memory bit set to 1. What this means is, with DAC on, any time a server wants to mount a database, there are a few ways it will attempt to communicate with other DAG members:
- If the starting DAG member can communicate with all other members, DACP bit switches to 1
- If the starting DAG member can communicate with another member, and that other member’s DACP bit is set to 1, starting DAG member DACP bit switches to 1
- If the starting DAG member can communicate with another member, and that other member’s DACP bits are set to 0, starting DAG member DACP bit remains at 0
Because of this, when the Primary DAG Servers come back online, they will need to either contact all other DAG members or contact a DAG member with DACP bit set to 1 in order to be in a state where it can begin mounting databases. Because the WAN is down, these Primary Datacenter DAG Servers that are now just coming back online won’t be able to mount databases because none of these servers will have that special memory bit set to 1. That memory bit will be set on one of the DAG Servers in the Secondary Site. Once WAN connectivity is restored, these Primary Datacenter DAG Servers will now be able to communicate with the DAG Server that happens to have that special memory bit set to 1 and now these DAG Servers will be allowed to mount databases.
Thankfully, in SP1, DAC will work with 2 node DAGs and multi-site DAGs that are using a stretched AD Site.
DAC and ForceQuorum
If you do not know what Forcequorum is, have a quick look at my blog post here. Essentially, forcequorum allows you to forcefully start a cluster when this cluster has lost quorum. You’re forcing it to bypass the Majority Node Set requirement to become operational. In CCR, forcequorum was used in a geographically dispersed CCR cluster. When the Primary Site went offline, you had to run forcequorum on the node in the Secondary Site and then set a new File Share Witness. This is similar in Exchange 2010 DAGs when the Primary Site goes offline.
The article here is entitled Datacenter Switchovers and is the article to use when planning Site Resiliency with Exchange 2010. You can see, in the procedure for terminating a failed site, there are two methods:
- When the DAG is in DAC mode:
- When the DAG isn’t in DAC mode
When looking at the procedures for when DAC is NOT enabled, there are more steps that have to be done which involve running clussvc commands. When looking at the procedures for when DAC is enabled, there are no steps which involve running clussv commands. This is because when you have DAC mode on, Exchange’s Site Resilient tasks allow it to perform these clussvc tasks in the background. As you can see, it is well worth it to ensure you have at least 3 DAG nodes in a DAG just to utilize DAC. But again, in Exchange 2010 SP1, DAC can be utilized with DAGs that contain two nodes.
Categorised as: Exchange, Microsoft
Leave a Reply
You must be logged in to post a comment.