Exchange 2010 Site Resilient DAGs and Majority Node Set Clustering – Part 1
http://www.shudnow.net/2011/08/05/exchange-2010-site-resilient-dags-and-majority-node-set-clustering-part-1/
I’ve talked about this topic in some of my other articles but wanted to create an article that talks specifically about this model and show several different examples in a Database Availability Group (DAG)’s tolerance for node and File Share Witness (FSW) failure. Many people don’t properly understand how the Majority Node Set Clustering Model works. In my article here, I talk about Database Activation Coordination Mode and have a section on Majority Node Set. In this article, I want to visibly show show some real world examples on how the Majority Node Set Clustering Model works. This will be a multi-part article and each Part will have its own example.
Part 1
Majority Node Set
Majority Node Set is a Windows Clustering Model such as the Shared Quorum Model, but different. Both Exchange 2007 and Exchange 2010 Clusters use Majority Node Set Clustering (MNS). This means that 50% of your votes (server votes and/or 1 file share witness) need to be up and running. The proper formula for this is (n / 2) + 1 where n is the number of DAG nodes within the DAG. With DAGs, if you have an odd number of DAG nodes in the same DAG (Cluster), you have an odd number of votes so you don’t have a witness. If you have an even number of DAGs nodes, you will have a file share witness in case half of your nodes go down, you have a witness who will act as that extra +1 number.
So let’s go through an example. Let’s say we have 3 servers. This means that we need (number of nodes which is 3 / 2) + 1 which equals 2 as you round down since you can’t have half a server/witness. This means that at any given time, we need 2 of our nodes to be online which means we can sustain only 1 (either a server or a file share witness) failure in our DAG. Now let’s say we have 4 servers. This means that we need (number of nodes which is 4 / 2) + 1 which equals 3. This means at any given time, we need 3 of our servers/witness to be online which means we can sustain 2 server failures or 1 server failure and 1 witness failure.
Real World Examples
Each of these examples will show DAG Models with a Primary Site and a Failover Site.
2 Node DAG (One in Primary and One in Failover)
In the following screenshot, we have 3 Servers. Two are Exchange 2010 Multi-Role Servers; one in the Primary Site and one on the Failover Site. The Cluster Service is running only on the two Exchange Multi-Role Servers. More specifically, it would run on the Exchange 2010 Servers that have the Mailbox Server Role. When Exchange 2010 utilizes an even number of Nodes, it utilizes Node Majority with File Share Witness. If you have dedicated HUB and/or HUB/CAS Servers, you can place the File Share Witness on those Servers. However, the File Share Witness cannot be placed on the Mailbox Server Role.
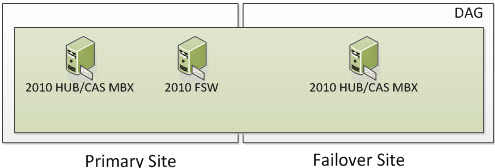
So now we have our three Servers; two of them being Exchange. This means we have two voters and a File Share Witness. Two of the Mailbox Servers that are running the cluster service are voters and the File Share Witness is just a witness that the voters use to determine cluster majority. So the question is, how many voters/servers can I lose? Well if you read the section on Majority Node Set (which you have to understand), you know the formula is (number of nodes /2) + 1. This means we have (2 Exchange Servers / 2) = 1 + 1 = 2. This means that 2 cluster objects must always be online for your Exchange Cluster to remain operational.
But now let’s say one of your Exchange Servers go offline. Well, you still have at least two cluster objects online. This means your cluster will be still be operational. If all users/services were utilizing the Primary Site, then everything continues to remain completely operational. If you were sending SMTP to the Failover Site or users were for some reason connecting to the Failover Site, they will need to be pointed to the Exchange Server in the Primary Site.
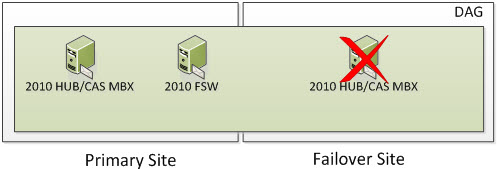
But what happens if you lose a second node? Well, based on the formula above we need to ensure we have 2 cluster objects operational at all times. At this time, the entire cluster goes offline. You need to go through steps provided in the site switchover process but in this case, you would be activating the Primary Site and specify a new Alternative File Share Witness Server that exists in the Primary Site so you can active the Exchange 2010 Server in the Primary Site. The DAG won’t actively use the File Share Witness but you should specify it anyways because part of the Failback process is re-adding the Primary Site Servers back to the DAG once they become operational.
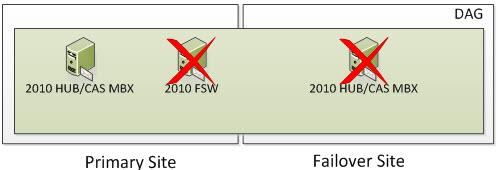
But what happens if you lose two nodes in the Primary Site? Well, based on the formula above we need to ensure we have 2 cluster objects operational at all times. At this time, the entire cluster goes offline. You need to go through steps provided in the site switchover process but in this case, you would be activating the Failover Site and specify a new Alternative File Share Witness Server that exists (or will exist) in the Failover Site so you can activate the Exchange 2010 Server in the Primary Site. The DAG won’t actively use the File Share Witness but you should specify it anyways because part of the Failback process is re-adding the Primary Site Servers back to the DAG once they become operational.
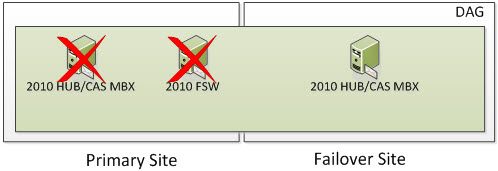
Once the Datacenter Switchover has occurred, you will be in a state that looks as such. An Alternate File Share Witness is not for redundancy for your 2010 FSW that was in your Primary Site. It’s used only during a Datacenter Switchover which is a manual process.
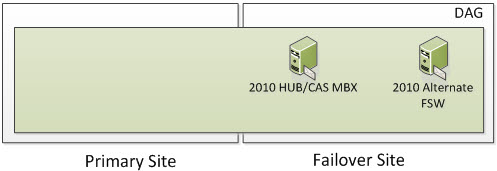
Once your Primary Site becomes operational, you will re-add the Primary DAG Server to the existing DAG which will still be using the 2010 Alternate FSW Server in the Failover Site and you will now be switched into a Node Majority with File Share Witness Cluster instead of just Node Majority. Remember I said with an odd number of DAG Servers, you will be in Node Majority and with an even number, the Cluster will automatically switch itself to Node Majority with File Share Witness? You will now be in a state that looks as such.
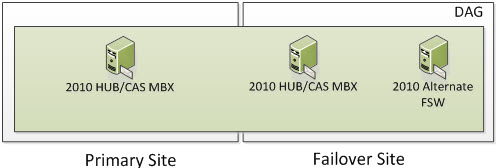
Part of the Failback Process would be to switch back to the old FSW Server in the Primary Site. Once done, you will be back into your original operational state.
As you can see with how this works, the question that may arise is where to put your FSW? Well, it should be in the Primary Site with the most users or the site that has the most important users. With that in mind, I bet another question arises? Well, why with the most users or the most important users? Because some environments may want to use the above with an Active/Active Model instead of an Active/Passive. Some databases may be activated in both sites. But, with that, if the WAN link goes down, the Exchange 2010 Server in the Failover Site loses quorum since it can’t contact at least 1 other voter. Again, you must have two voters online. This also means that each voter must be able to see one other voter. Because of that, the Exchange 2010 Server will go completely offline.
To survive this, you really must use 2 different DAGs. One DAG where the FSW is in the First Site and a second DAG where its FSW is in the Second Site. Users that live in the First Active Site would primarily be using the Exchange 2010 DAG Members in the First Active Site. Users that live in the Second Active Site would primarily be using the Exchange 2010 DAG Members in the Second Active Site. This way, if anything happens with the WAN link, users in the First Active Site would still be operational as the FSW for their DAG is in the First Active Site and DAG 1 would maintain Qourum. Users in the Second Active Site would still be operational as the FSW for their DAG is in the Second Active Site and DAG 2 would maintain Quorum.
Note: This would require twice the amount of servers since a DAG Member cannot be a part of more than one DAG. As shown below, each visual representation below of a 2010 HUB/CAS/MBX is a separate server.
The Multi-DAG Model would look like this.

Categorised as: Exchange, Microsoft
Leave a Reply
You must be logged in to post a comment.