Recovering from Server 2008 CCR Cluster Failure with Forcequorum
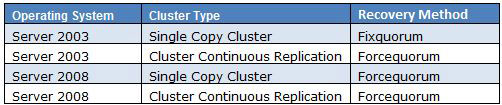
Server 2003 and Server 2008 Cluster Models are different in the following ways:
- Server 2003 utilizes the Shared Quorum Model for Single Copy Clusters and utilizes Majority Node Set for Cluster Continuous Replication Clusters.
- Server 2008 utilizes Majority Node Set for both Single Copy Clusters and Cluster Continuous Replication Clusters. When using Single Copy Clusters with Server 2008, it is recommended to use Node Majority with Disk Witness. When using Cluster Continuous Replication, it is recommended to use Node Majority with File Share Witness.
When working with Cluster recovery methods, the method differentiates a little bit from when using the Shared Quorum Model than using the Majority Node Set Model.
In this article, I will focus on recovering from Server 2008 Cluster Continuous Replication Site Failure (kind of — more info later). I was debating on creating this article as a multi-part series for setting up CCR and then showing how to recover using Forcequorum, but decided not to. This is because I believe Andy Grogan does a fine job in his how to set up CCR on Server 2008 that I decided not to. You can read Andy’s great article here.
Forcequorum Changes in Windows 2003 and Windows 2008
One thing I do want to mention is that forcequorum in Windows 2003 and 2008 differentiate quite a bit. While the functionality provides the same result, some things in the background are quite different. First of all, in Windows 2003, /forcequorum can be used as maintenance switch. In Windows 2008, this is no longer the case. When running /forcequorum on a Windows 2008 Cluster Node, the paxos for the cluster is increased; you can call this inifnity. What this means is, is that the node you run /forcequorum on becomes the master/authoritative node for any cluster joins. Because of this, it is imperative that your cluster node you run /forcequorum on is a fully configured cluster node. More information can be found on this here. This to Tim McMichael for making me aware of this change to forcequorum in Windows 2008.
An example of the above would be the following:
You have a 4 node Single Copy Cluster. You have installed Windows Clustering Services on all 4 nodes but you have only installed Exchange 2007 on 3 nodes. On the 4th node you have not installed Exchange on, you run /forcequorum. That 4th node is now the authoritative copy for all cluster nodes. Whenever the cluster service starts, it performs a join operation. Because the 4th node is now the authoritative/master node for cluster configuration, your 3 other servers will have Exchange failures because when their cluster service starts up the next time, the cluster information for Exchange on that server is wiped due to the authoritative copy on the 4th Exchange node being wiped. That is why, in Windows 2008, you need to ensure that the 2008 node you run /forcequorum on is fully configured. Think of it as doing an authoritative copy on a Domain Controller that has been shut down for 2 weeks. You’ll lose any password changes, accounts that have been created, accounts that were deleted will be back, and any other AD related information in the last two weeks will be back.
The Lab
While my lab is all in one site, the recoverability method is similar as it would be if it were a geographically dispersed cluster. When the Exchange Servers in one site fails, that means the Active CCR in one site went down and the File Share Witness went down. In a Geo-Cluster, your Passive and now the new Active Node (at least it should be the new Active… but read on) will not be able to start.
Why is this? Well, a Majority Node Set Cluster requires 50% of the Nodes + 1 to be up. Because 2/3 witnesses are down, the cluster services on your Passive Node will not start (which is what I meant by it should be the new Active). Now what about the kind-of I spoke about earlier? Well, since all the services are in one site, I will be skipping the method where I re-create the file share witness on a Hub Transport Server in the original datacenter and utilize the new FSW I already have created. If you were indeed doing Geo-Cluster, you may want to re-provision the FSW back on the original node to get everything moved back over to the main site. That’s the only difference. This will make more sense as you read on as I show how to both move the FSW back to the original node and the method we actually do in regards to skipping that process.
So to re-iterate, my lab is in one site and will be showing you how to recover and provide additional information on what you would do if you wanted to re-provision your FSW back to a Hub Transport Server if you were failing back everything to your original datacenter. To start this process, I will pause my Active Node and my delete the file share witness that exists on my Hub Transport Server. To recover, I will do a forcequorum on my second node, re-create the file share witness, have my cluster point to the new file share witness, bring up my old Active Node which will now be the new Passive Node, and have it point to the new file share witness.
The Environment
Before we dive into the process, let’s talk a little bit about the environment. I have two Domain Controllers, one Hub Transport Server running on Server 2003 x64 R2 SP2, and two CCR Mailbox Servers running on Server 2008 x64. All this is being run on Hyper-V managed by System Center Virtual Machine Manager 2008 RTM.
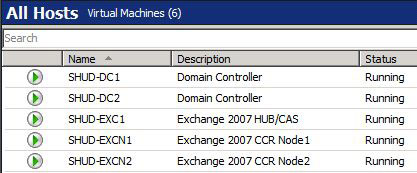
On SHUD-EXC1, our File Share Witness is located in the FSM_EXCluster file share. This share has full permissions to our Cluster which is named EXCluster$. Our Security/NTFS Permissions are set to Administrator and EXCluster$ full control. Our Exchange CMS is named Cluster. Yes… I know… The names are backwards and the cluster name should be Cluster while the Exchange CMS should be EXCluster. Oops I guess…
Taking a look at our Cluster in the Exchange Management Shell, we can see that our Cluster is currently healthy.
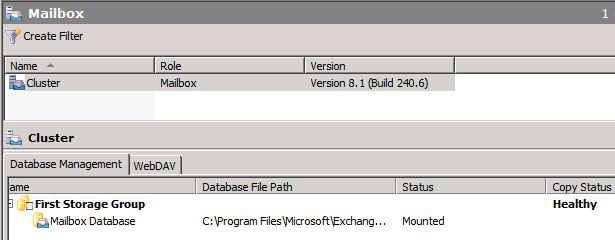
We can also see that moving the Cluster from SHUD-EXCN1 to SHUD-EXCN2 is successful meaning that the Cluster is indeed healthy.
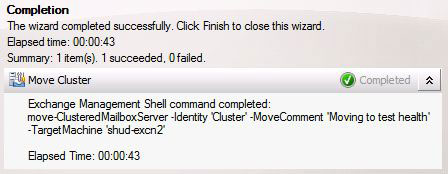
I did move the Cluster back to SHUD-EXCN1 though just to make sure failover is working to and from both nodes.
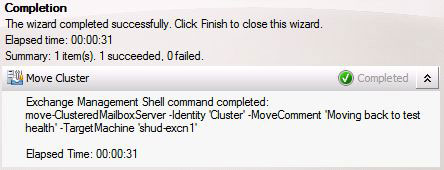
Ok, hooray! We have a successful and healthy cluster to test on. So let’s get on with the good stuff.
Failing the Cluster
First thing I’m going to do is delete the file share. We can see the share no longer exists on SHUD-EXC1.
Now, let’s pause SHUD-EXCN1 which is the current Active CCR Cluster Node.
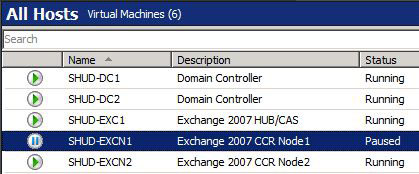
We can check the services and event log on SHUD-EXCN2. We can see that the Information Store service won’t start and we get quite a few event log failures such as the following (and there’s more than just what’s below).

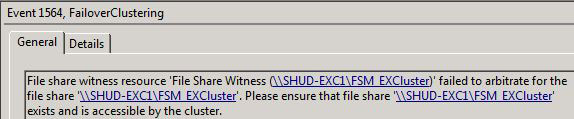
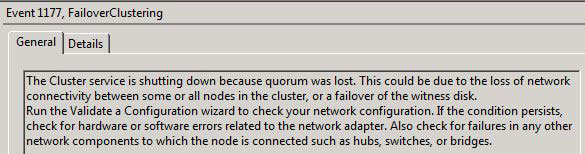
Recover the Cluster on SHUD-EXCN2
So the first thing we want to do is a Forcequorum on SHUD-EXCN2. You typically could bring up SHUD-EXCN1 but we’re acting as if SHUD-EXCN1 is having issues and we can’t get it up right now and we really need to get our cluster our to serve clients. Guidance on doing a forcequorum on both Server 2003 and Server 2008 for Exchange 2007 can be located here.
We will be performing the following steps to get our SHUD-EXCN2 running properly:
- Provision a new share for FSW on SHUD-EXC1. If you are doing a GeoCluster, you can do this in Site B which is where your Passive Node would be.
- Force quorum on SHUD-EXCN2 by running the following command: net start clussvc /forcequorum
- Use the Configure Cluster Quorum Settings wizard to configure the SHUD-EXCN2 to use the new FSW share on SHUD-EXC1.
- Reboot SHUD-EXCN2.
- Start the clustered mailbox server.
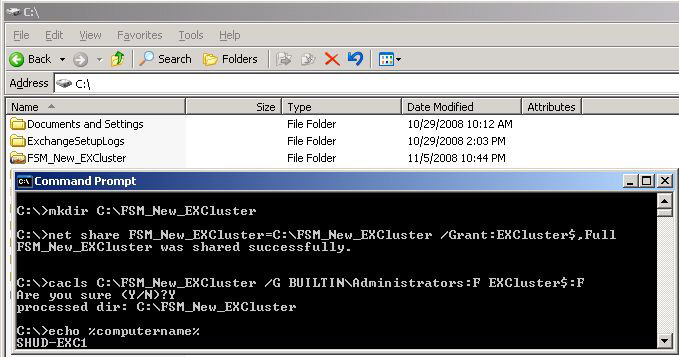
Provision New Share
We can run the following commands to re-create the folder for the FSW, share it out, and apply the correct permissions.
mkdir C:FSM_New_EXCluster
net share FSM_New_EXCluster=C:FSM_New_EXCluster /Grant:EXCluster$,Full
cacls C:FSM_New_EXCluster /G BUILTINAdministrators:F EXCluster$:F
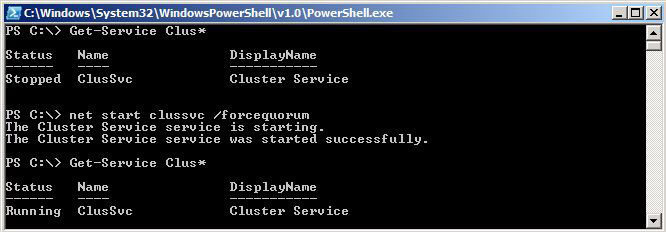
Forcequorum on SHUD-EXCN2
Now is the time to force our cluster services to start on our soon to be Active Node which was previously the Passive Node. We will do this by running the following command: net start clussvc /forcequorum.
Configure our new Cluster Quorum
Go into the Failover Cluster Management tool in Start > Administrative Tools. Then Right-Click on our Cluster FQDN > More Actions > Configure Cluster Quorum Settings.
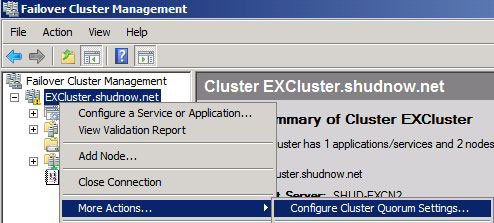
Choose Node and File Share Majority. Click Next to Continue.
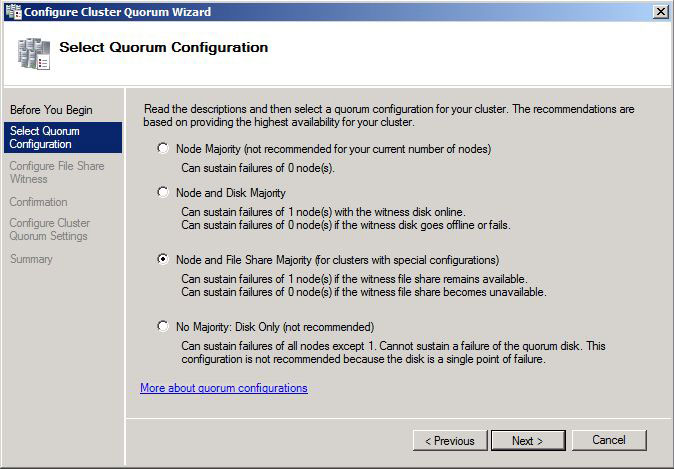
Enter the location for the new File Share. Click Next to Continue.
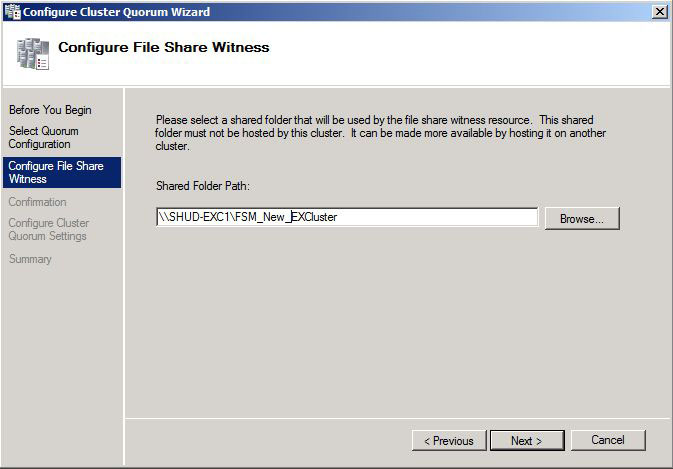
You can go through the rest of the prompts and we will see the Cluster Quorum has successfully been configured to point to the new File Share Witness.
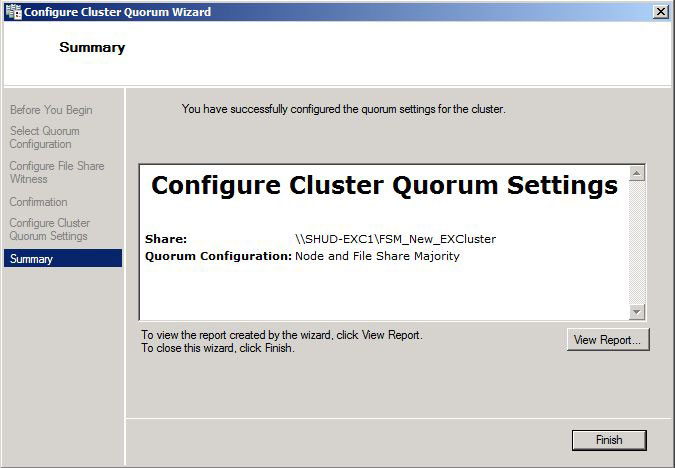
Remaining Steps
The remaining steps are very simple. Reboot the node and start the Clustered Mailbox Server. Upon restarting, you will see that the Cluster Service is successfully started. Congratulations. This means the connection to the File Share Witness is working because have have over 50% of our witnesses (2/3 is > 50%) online.
We can then verify we have Outlook Client Connectivity. And as the screenshot shows, we do successfully have Outlook Connectivity. Hooray!
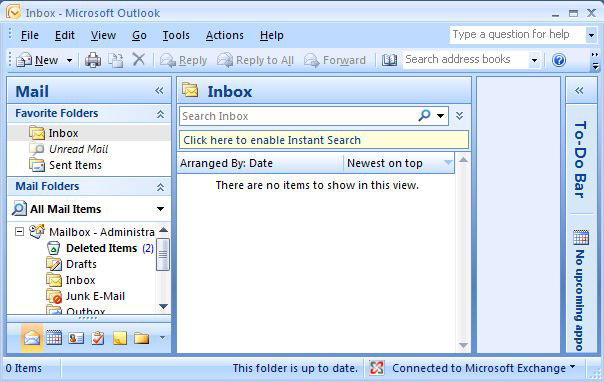
Unfortunately though, we can still have our old Active Node SHUD-EXCN1 down as we can see in the Exchange Management Console.
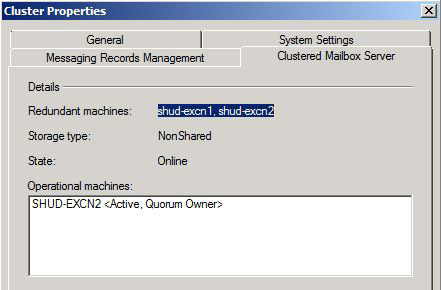
Bringing SHUD-EXCN1 Back Online
Now we need to get SHUD-EXCN1 back online and in a healthy replication state. If you did all the above in a real Geo-Cluster, you’d want to run the following steps:
- Provision a new share on a HUB in Datacenter A.
- Bring SHUD-EXCN1 online.
- Reconfigure the cluster quorum to use the FSW share on HUB in Datacenter A.
- Stop the clustered mailbox server.
- Move the Cluster Group from SHUD-EXCN2 to SHUD-EXCN1.
- Move the clustered mailbox server from SHUD-EXCN2 to SHUD-EXCN1.
- Start the clustered mailbox server.
But because we’re running in the same site in the lab, we’re just going to skip the creation of the new FSW and use our existing one. Because of this, our steps will be:
- Bring SHUD-EXCN1 online.
- Stop the clustered mailbox server.
- Move the Cluster Group from SHUD-EXCN2 to SHUD-EXCN1.
- Move the clustered mailbox server from SHUD-EXCN2 to SHUD-EXCN1.
- Start the clustered mailbox server.
So let’s bring up SHUD-EXCN1.
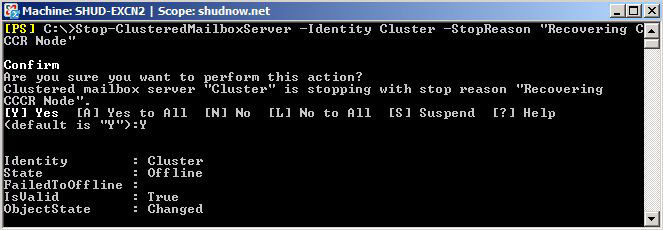
Now on SHUD-EXCN2, in the Exchange Management Shell, we will run the following command to stop the Clustered Mailbox Server (GUI/CLI method here):
Stop-ClusteredMailboxServer -Identity Cluster -StopReason:Recovering CCR Node”
Let’s move the Clustered Mailbox Server to SHUD-EXCN1 using the following command (GUI/CLI method here):
Move-ClusteredMailboxServer -Identity Cluster -TargetMachine SHUD-EXCN1 -MoveComment “Moving CCR”
We will also need to move the default Cluster Group to SHUD-EXCN1 using the following command:
cluster group “Cluster Group” /move:SHUD-EXCN1
We willl then want to verify both the Cluster Mailbox Server (Cluster) and Cluster Group are both on SHUD-EXCN1. Don’t forget that we did a Stop-ClusteredMailboxServer so we should see that Offline and the Cluster Group online.
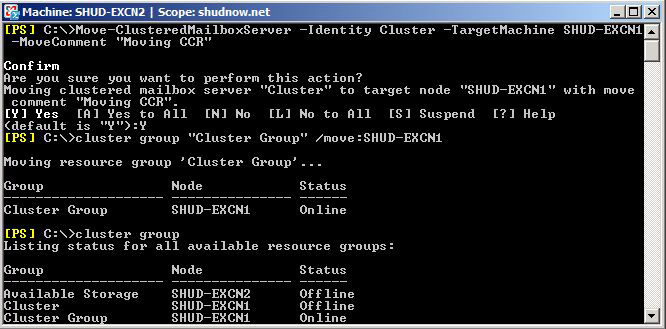
We now want to start the Clustered Mailbox Server by running the following command:
Start-ClusteredMailboxServer -Identity Cluster
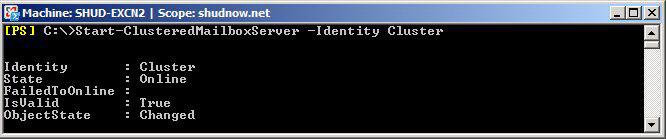
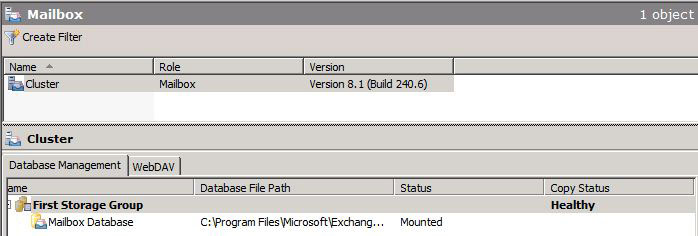
Now let’s verify that our Cluster is in a healthy replication state.
And to just make sure, let’s verify Outlook Connectivity still works.
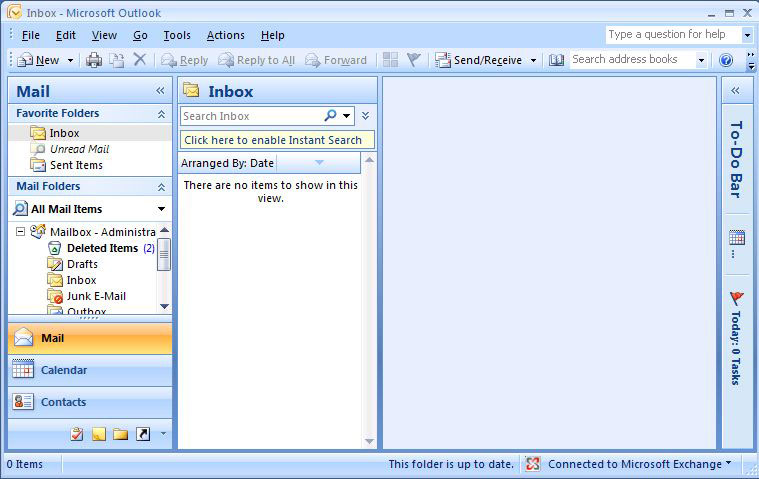
Congrats, you now have a completely restored CCR Cluster!
Categorised as: Exchange, Microsoft
Leave a Reply
You must be logged in to post a comment.