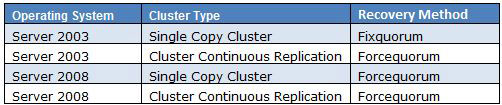
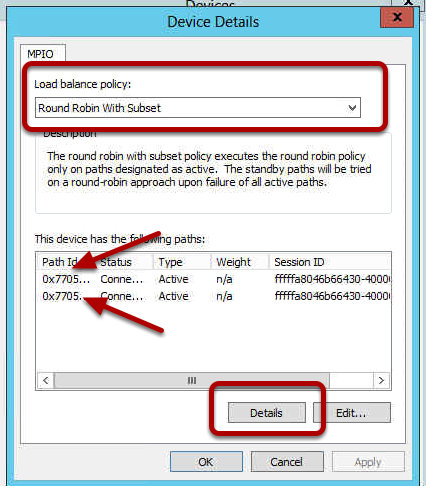
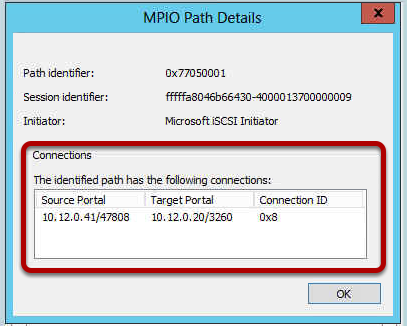
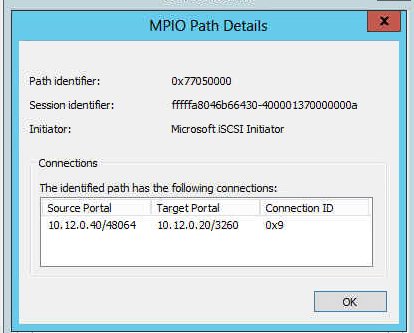
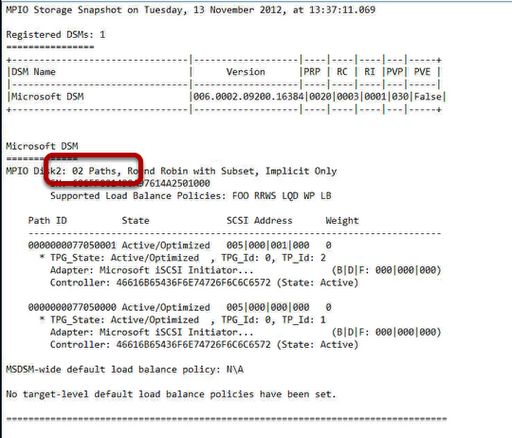
Server 2003 and Server 2008 Cluster Models are different in the following ways:
Server 2003 utilizes the Shared Quorum Model for Single Copy Clusters and utilizes Majority Node Set for Cluster Continuous Replication Clusters.
Server 2008 utilizes Majority Node Set for both Single Copy Clusters and Cluster Continuous Replication Clusters. When using Single Copy Clusters with Server 2008, it is recommended to use Node Majority with Disk Witness. When using Cluster Continuous Replication, it is recommended to use Node Majority with File Share Witness.
When working with Cluster recovery methods, the method differentiates a little bit from when using the Shared Quorum Model than using the Majority Node Set Model.
In this article, I will focus on recovering from Server 2008 Cluster Continuous Replication Site Failure (kind of — more info later). I was debating on creating this article as a multi-part series for setting up CCR and then showing how to recover using Forcequorum, but decided not to. This is because I believe Andy Grogan does a fine job in his how to set up CCR on Server 2008 that I decided not to. You can read Andy’s great article here.
Forcequorum Changes in Windows 2003 and Windows 2008
One thing I do want to mention is that forcequorum in Windows 2003 and 2008 differentiate quite a bit. While the functionality provides the same result, some things in the background are quite different. First of all, in Windows 2003, /forcequorum can be used as maintenance switch. In Windows 2008, this is no longer the case. When running /forcequorum on a Windows 2008 Cluster Node, the paxos for the cluster is increased; you can call this inifnity. What this means is, is that the node you run /forcequorum on becomes the master/authoritative node for any cluster joins. Because of this, it is imperative that your cluster node you run /forcequorum on is a fully configured cluster node. More information can be found on this here. This to Tim McMichael for making me aware of this change to forcequorum in Windows 2008.
An example of the above would be the following:
You have a 4 node Single Copy Cluster. You have installed Windows Clustering Services on all 4 nodes but you have only installed Exchange 2007 on 3 nodes. On the 4th node you have not installed Exchange on, you run /forcequorum. That 4th node is now the authoritative copy for all cluster nodes. Whenever the cluster service starts, it performs a join operation. Because the 4th node is now the authoritative/master node for cluster configuration, your 3 other servers will have Exchange failures because when their cluster service starts up the next time, the cluster information for Exchange on that server is wiped due to the authoritative copy on the 4th Exchange node being wiped. That is why, in Windows 2008, you need to ensure that the 2008 node you run /forcequorum on is fully configured. Think of it as doing an authoritative copy on a Domain Controller that has been shut down for 2 weeks. You’ll lose any password changes, accounts that have been created, accounts that were deleted will be back, and any other AD related information in the last two weeks will be back.
The Lab
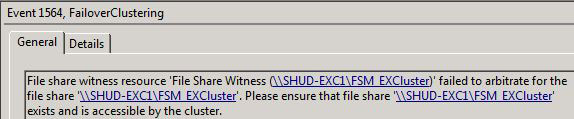
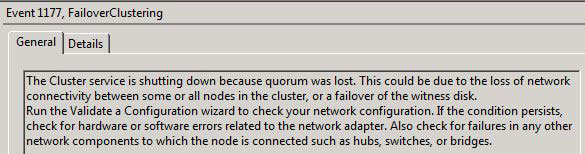
While my lab is all in one site, the recoverability method is similar as it would be if it were a geographically dispersed cluster. When the Exchange Servers in one site fails, that means the Active CCR in one site went down and the File Share Witness went down. In a Geo-Cluster, your Passive and now the new Active Node (at least it should be the new Active… but read on) will not be able to start.
Why is this? Well, a Majority Node Set Cluster requires 50% of the Nodes + 1 to be up. Because 2/3 witnesses are down, the cluster services on your Passive Node will not start (which is what I meant by it should be the new Active). Now what about the kind-of I spoke about earlier? Well, since all the services are in one site, I will be skipping the method where I re-create the file share witness on a Hub Transport Server in the original datacenter and utilize the new FSW I already have created. If you were indeed doing Geo-Cluster, you may want to re-provision the FSW back on the original node to get everything moved back over to the main site. That’s the only difference. This will make more sense as you read on as I show how to both move the FSW back to the original node and the method we actually do in regards to skipping that process.
So to re-iterate, my lab is in one site and will be showing you how to recover and provide additional information on what you would do if you wanted to re-provision your FSW back to a Hub Transport Server if you were failing back everything to your original datacenter. To start this process, I will pause my Active Node and my delete the file share witness that exists on my Hub Transport Server. To recover, I will do a forcequorum on my second node, re-create the file share witness, have my cluster point to the new file share witness, bring up my old Active Node which will now be the new Passive Node, and have it point to the new file share witness.
The Environment
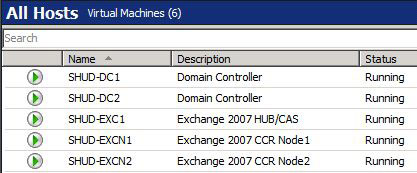
Before we dive into the process, let’s talk a little bit about the environment. I have two Domain Controllers, one Hub Transport Server running on Server 2003 x64 R2 SP2, and two CCR Mailbox Servers running on Server 2008 x64. All this is being run on Hyper-V managed by System Center Virtual Machine Manager 2008 RTM.
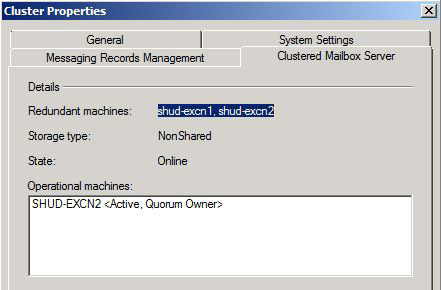
On SHUD-EXC1, our File Share Witness is located in the FSM_EXCluster file share. This share has full permissions to our Cluster which is named EXCluster$. Our Security/NTFS Permissions are set to Administrator and EXCluster$ full control. Our Exchange CMS is named Cluster. Yes… I know… The names are backwards and the cluster name should be Cluster while the Exchange CMS should be EXCluster. Oops I guess…
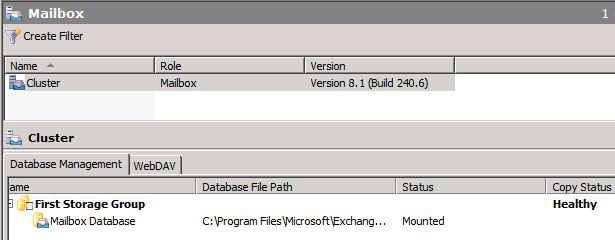
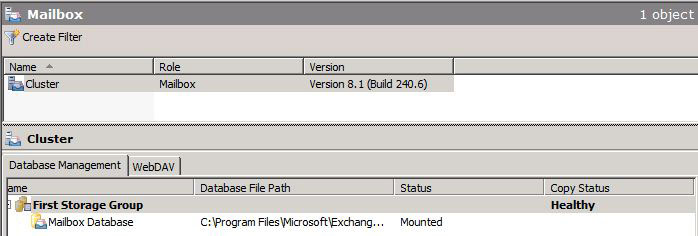
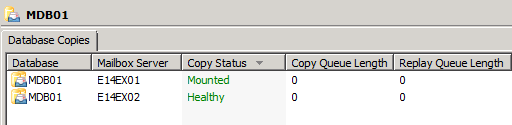
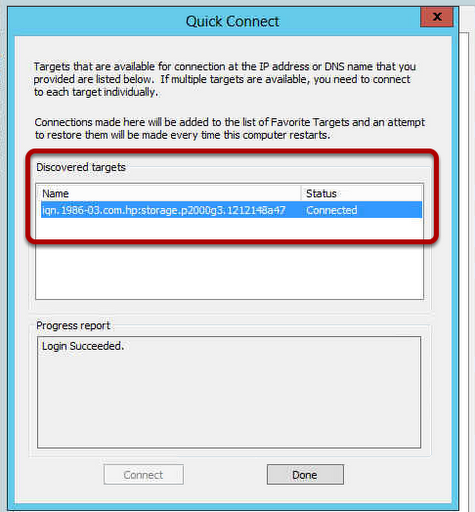
Taking a look at our Cluster in the Exchange Management Shell, we can see that our Cluster is currently healthy.
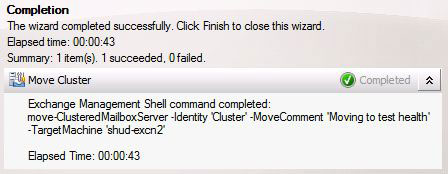
We can also see that moving the Cluster from SHUD-EXCN1 to SHUD-EXCN2 is successful meaning that the Cluster is indeed healthy.
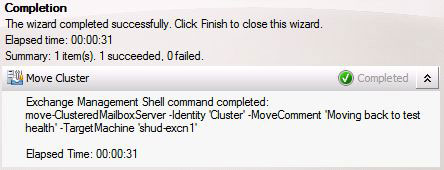
I did move the Cluster back to SHUD-EXCN1 though just to make sure failover is working to and from both nodes.
Ok, hooray! We have a successful and healthy cluster to test on. So let’s get on with the good stuff.
Failing the Cluster
First thing I’m going to do is delete the file share. We can see the share no longer exists on SHUD-EXC1.
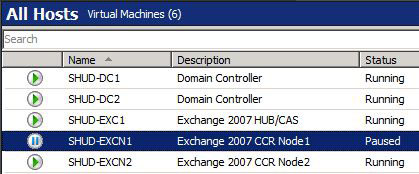
Now, let’s pause SHUD-EXCN1 which is the current Active CCR Cluster Node.
We can check the services and event log on SHUD-EXCN2. We can see that the Information Store service won’t start and we get quite a few event log failures such as the following (and there’s more than just what’s below).
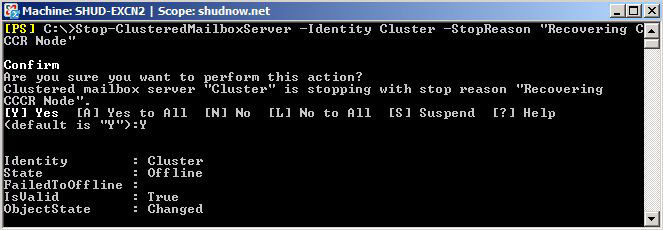
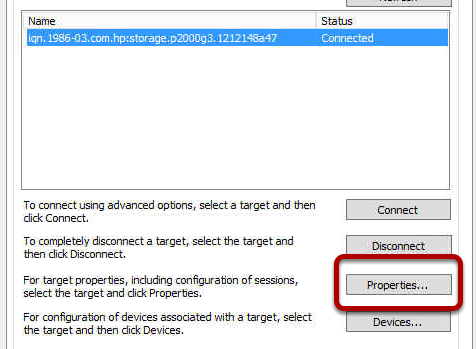
Recover the Cluster on SHUD-EXCN2
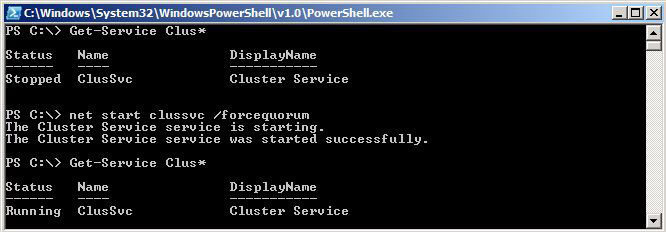
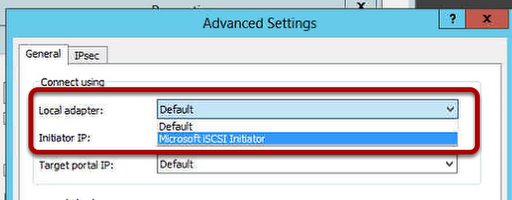
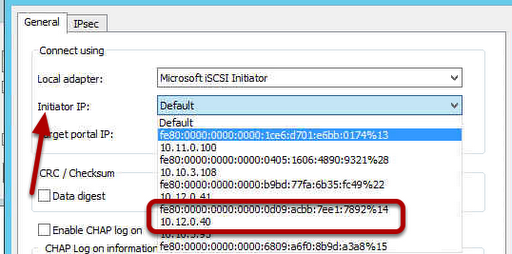
So the first thing we want to do is a Forcequorum on SHUD-EXCN2. You typically could bring up SHUD-EXCN1 but we’re acting as if SHUD-EXCN1 is having issues and we can’t get it up right now and we really need to get our cluster our to serve clients. Guidance on doing a forcequorum on both Server 2003 and Server 2008 for Exchange 2007 can be located here.
We will be performing the following steps to get our SHUD-EXCN2 running properly:
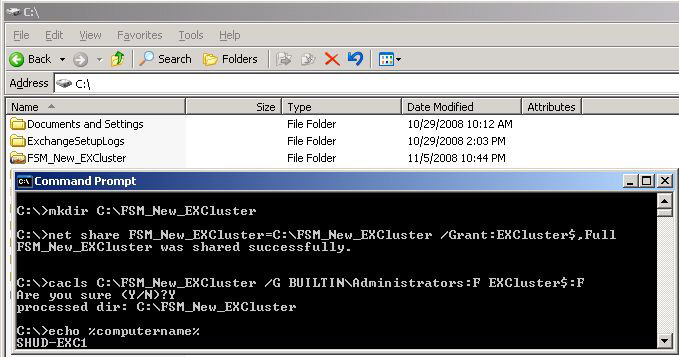
Provision a new share for FSW on SHUD-EXC1. If you are doing a GeoCluster, you can do this in Site B which is where your Passive Node would be.
Force quorum on SHUD-EXCN2 by running the following command: net start clussvc /forcequorum
Use the Configure Cluster Quorum Settings wizard to configure the SHUD-EXCN2 to use the new FSW share on SHUD-EXC1.
Reboot SHUD-EXCN2.
Start the clustered mailbox server.
Provision New Share
We can run the following commands to re-create the folder for the FSW, share it out, and apply the correct permissions.
Now is the time to force our cluster services to start on our soon to be Active Node which was previously the Passive Node. We will do this by running the following command: net start clussvc /forcequorum.
Configure our new Cluster Quorum
Go into the Failover Cluster Management tool in Start > Administrative Tools. Then Right-Click on our Cluster FQDN > More Actions > Configure Cluster Quorum Settings.
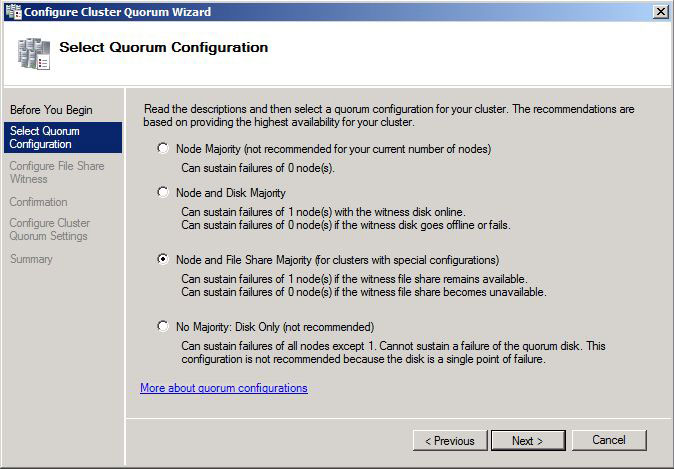
Choose Node and File Share Majority. Click Next to Continue.
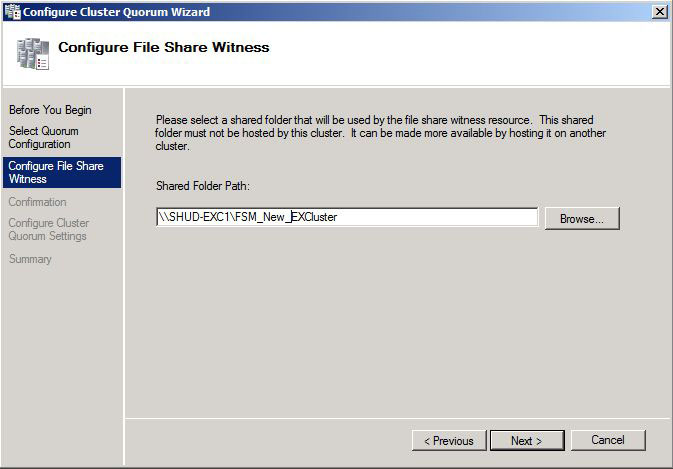
Enter the location for the new File Share. Click Next to Continue.
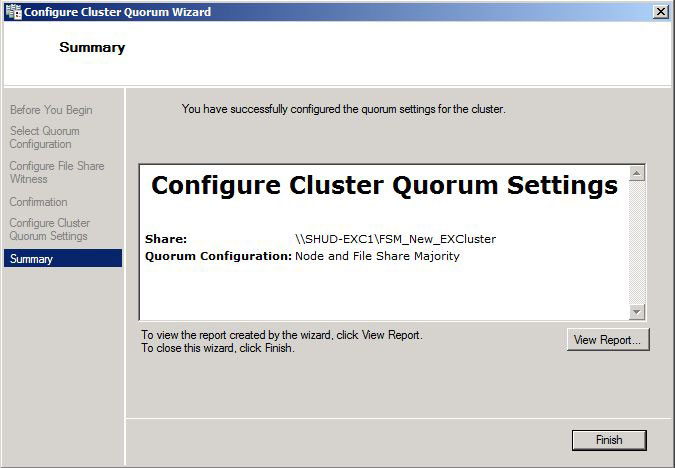
You can go through the rest of the prompts and we will see the Cluster Quorum has successfully been configured to point to the new File Share Witness.
Remaining Steps
The remaining steps are very simple. Reboot the node and start the Clustered Mailbox Server. Upon restarting, you will see that the Cluster Service is successfully started. Congratulations. This means the connection to the File Share Witness is working because have have over 50% of our witnesses (2/3 is > 50%) online.
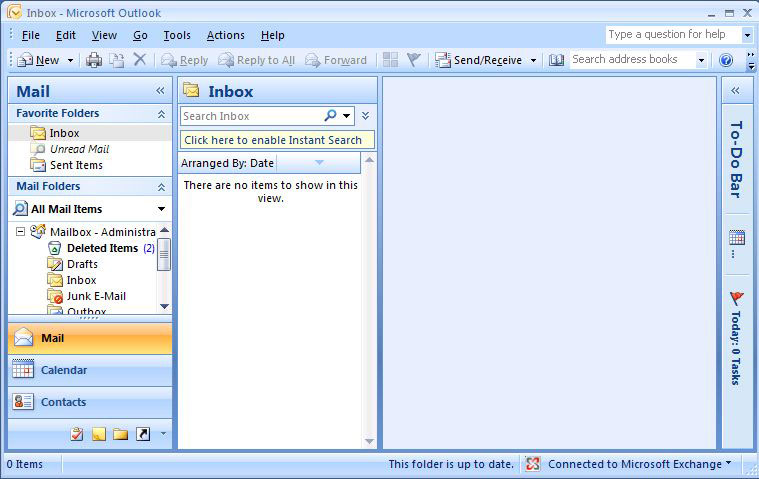
We can then verify we have Outlook Client Connectivity. And as the screenshot shows, we do successfully have Outlook Connectivity. Hooray!
Unfortunately though, we can still have our old Active Node SHUD-EXCN1 down as we can see in the Exchange Management Console.
Bringing SHUD-EXCN1 Back Online
Now we need to get SHUD-EXCN1 back online and in a healthy replication state. If you did all the above in a real Geo-Cluster, you’d want to run the following steps:
Provision a new share on a HUB in Datacenter A.
Bring SHUD-EXCN1 online.
Reconfigure the cluster quorum to use the FSW share on HUB in Datacenter A.
Stop the clustered mailbox server.
Move the Cluster Group from SHUD-EXCN2 to SHUD-EXCN1.
Move the clustered mailbox server from SHUD-EXCN2 to SHUD-EXCN1.
Start the clustered mailbox server.
But because we’re running in the same site in the lab, we’re just going to skip the creation of the new FSW and use our existing one. Because of this, our steps will be:
Bring SHUD-EXCN1 online.
Stop the clustered mailbox server.
Move the Cluster Group from SHUD-EXCN2 to SHUD-EXCN1.
Move the clustered mailbox server from SHUD-EXCN2 to SHUD-EXCN1.
Start the clustered mailbox server.
So let’s bring up SHUD-EXCN1.
Now on SHUD-EXCN2, in the Exchange Management Shell, we will run the following command to stop the Clustered Mailbox Server (GUI/CLI method here):
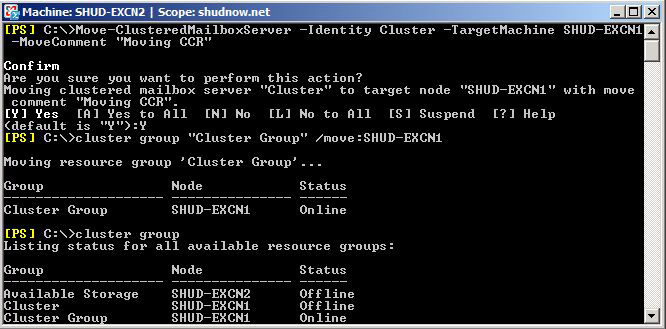
We will also need to move the default Cluster Group to SHUD-EXCN1 using the following command:
cluster group “Cluster Group” /move:SHUD-EXCN1
We willl then want to verify both the Cluster Mailbox Server (Cluster) and Cluster Group are both on SHUD-EXCN1. Don’t forget that we did a Stop-ClusteredMailboxServer so we should see that Offline and the Cluster Group online.
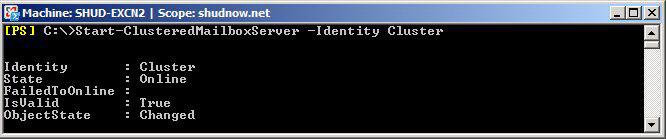
We now want to start the Clustered Mailbox Server by running the following command:
Start-ClusteredMailboxServer -Identity Cluster
Now let’s verify that our Cluster is in a healthy replication state.
And to just make sure, let’s verify Outlook Connectivity still works.
Congrats, you now have a completely restored CCR Cluster!
Exchange 2010 introduced a vast amount of changes to the High Availability model with the addition of the Database Availability Group (DAG). Some features of the DAG are having up to 16 members, automatic database *over to another site as long as you still have quorum, and much more. Exchange also introduced Database Activation Coordination (DAC) mode as an optional addition to the new High Availability model to prevent split brain syndrome from occurring during a site switchover when utilizing a multi-site DAG configuration with at least 3 DAG members and more than one Active Directory Site. DAC is off by default and in Exchange 2010 RTM it should not be enabled for:
2 member DAGs
Non-Multisite DAGs
Multi-site DAGs that are in the same stretched Active Directory Site
In Exchange 2010 SP1, the following changes are introduced and supported for DAC:
DAGs that contain 2 or more members
DAGs that are stretched across a single AD Site
Majority Node Set
Before we understand how DAC works, we really have to understand the Cluster Model that DAGs utilize. Both Exchange 2007 and Exchange 2010 Clusters use Majority Node Set Clustering (MNS). This means that 50% of your votes (server votes and/or 1 file share witness) need to be up and running. The proper formula for this is (n / 2) + 1 where n is the number of DAG nodes within the DAG. With DAGs, if you have an odd number of DAG nodes in the same DAG (Cluster), you have an odd number of votes so you don’t have a witness. If you have an even number of DAGs nodes, you will have a file share witness in case half of your nodes go down, you have a witness who will act as that extra +1 number.
So let’s go through an example. Let’s say we have 3 servers. This means that we need (number of nodes which is 3 / 2) + 1 which equals 2 as you round down since you can’t have half a server/witness. This means that at any given time, we need 2 of our nodes to be online which means we can sustain only 1 (either a server or a file share witness) failure in our DAG. Now let’s say we have 4 servers. This means that we need (number of nodes which is 4 / 2) + 1 which equals 3. This means at any given time, we need 3 of our servers/witness to be online which means we can sustain 2 server failures or 1 server failure and 1 witness failure.
Note: Exchange 2010 DAGs do not use the term Majority Node Set anymore. That term is deprecated and is now called Node Majority or Node Majority with File Share Witness.
Database Activation Coordination (DAC)
In short, DAC mode is enabled when you have at least 3 members to prevent split brain syndrome. It’s as simple as that. Let’s take a look at an example and see how DAC can help. The longer explanation below talks about this specific model.
Prevention of Split Brain Syndrome
Short Explanation
When the Primary Site goes offline (or we lose too many servers – refer to Majority Node Set above), the Secondary Site will need to be manually activated should you make the choice that a secondary site activation will be required depending on the magnitude of the failure and how long you anticipate the primary site or servers there will be down. But, when the Primary Site comes back online, the WAN link may be offline. Because the Primary Site’s Exchange Servers don’t necessarily know about the Manual Site Switchover, they will come up thinking they have Quorum since the Primary Site has the majority of the servers and they are still connected to the old FSW. Because of this, they will begin to mount databases since to them, they still have Quorum.
DAC mode will enable the usage of a new protocol, Database Activation Coordination Protocol (DACP). This means that DAG members start up with a special memory bit of 0. They need to contact another DAG node with this special memory bit set to 1. This memory bit will be set to 1 on one of the DAG members in the Secondary Site since that site is hosting active databases. Because the WAN link is down, the Primary Site’s DAG members that just came online won’t be able to contact this DAG member with the special memory bit set to 1. Because of this, they won’t be able to mount databases. The WAN link will have to come back online which means the Primary Site’s DAG members will now be able to contact the DAG member that has the special memory bit set to 1 which will now allow the Primary Site’s DAG Members to be in a state where they are allowed to mount databases.
Longer Explanation
We can see in this example, there are 5 DAG nodes and no FSW as we have an odd number of DAG nodes. Our entire Primary Datacenter Fails (or we lose too many servers – in our case, this would be (5 / 2) + 1 which means 3 of our nodes need to remain operational for the DAG to remain operational), the Secondary Site will need to be manually activated should you make the choice that a secondary site activation will be required depending on the magnitude of the failure and how long you anticipate the primary site or servers there will be down.
Part of the switchover process will have us shrink the DAG by removing the DAG nodes in the Primary Site from the cluster so all that remain of the existing 2 DAG nodes in the Secondary Site. Instructions for shrinking the DAG and doing a manual site actiavtion is locatedhere. Should we decide to proceed with a a manual site switchover , we will provision the FSW in the secondary site during manual site activation to the secondary datacenter. But what happens if the Primary Site’s Exchange Servers come back online? They will think they have majority because the primary site has the majority of the servers and the FSW is located there. Because of this, when they start up, they will begin mounting databases.
Now this is where DAC comes in. Without DAC enabled, the Primary Site’s Exchange Servers would indeed come online, think they have majority, and begin mounting databases and you run into a split-brain syndrome scenario. This is because when power is restored to the datacenter, the servers will usually come up before WAN connectivity is fully restored. The servers cannot communicate with each other between the sites to see that the active databases are already mounted, and because of that, the Primary Exchange Servers will see they have majority since the majority of your servers and your FSW should be in the Primary Site, and mount the databases.
If the servers were allowed to mount databases, and you ran into a split-brain scenario, something called Database Divergence would occur. Database Divergence is where the databases in the primary site would become different from the secondary site causing the need for a reseed from the authority database which would cause some database loss from the new database that went into the diverged database due to split-brain from occurring.
The way DAC works, is that all servers have a new protocol known as Database Activation Coordination Protocol (DACP). One of the DAG Nodes will always have a special memory bit set to 1. What this means is, with DAC on, any time a server wants to mount a database, there are a few ways it will attempt to communicate with other DAG members:
If the starting DAG member can communicate with all other members, DACP bit switches to 1
If the starting DAG member can communicate with another member, and that other member’s DACP bit is set to 1, starting DAG member DACP bit switches to 1
If the starting DAG member can communicate with another member, and that other member’s DACP bits are set to 0, starting DAG member DACP bit remains at 0
Because of this, when the Primary DAG Servers come back online, they will need to either contact all other DAG members or contact a DAG member with DACP bit set to 1 in order to be in a state where it can begin mounting databases. Because the WAN is down, these Primary Datacenter DAG Servers that are now just coming back online won’t be able to mount databases because none of these servers will have that special memory bit set to 1. That memory bit will be set on one of the DAG Servers in the Secondary Site. Once WAN connectivity is restored, these Primary Datacenter DAG Servers will now be able to communicate with the DAG Server that happens to have that special memory bit set to 1 and now these DAG Servers will be allowed to mount databases.
Thankfully, in SP1, DAC will work with 2 node DAGs and multi-site DAGs that are using a stretched AD Site.
DAC and ForceQuorum
If you do not know what Forcequorum is, have a quick look at my blog post here. Essentially, forcequorum allows you to forcefully start a cluster when this cluster has lost quorum. You’re forcing it to bypass the Majority Node Set requirement to become operational. In CCR, forcequorum was used in a geographically dispersed CCR cluster. When the Primary Site went offline, you had to run forcequorum on the node in the Secondary Site and then set a new File Share Witness. This is similar in Exchange 2010 DAGs when the Primary Site goes offline.
The article here is entitled Datacenter Switchovers and is the article to use when planning Site Resiliency with Exchange 2010. You can see, in the procedure for terminating a failed site, there are two methods:
When the DAG is in DAC mode:
When the DAG isn’t in DAC mode
When looking at the procedures for when DAC is NOT enabled, there are more steps that have to be done which involve running clussvc commands. When looking at the procedures for when DAC is enabled, there are no steps which involve running clussv commands. This is because when you have DAC mode on, Exchange’s Site Resilient tasks allow it to perform these clussvc tasks in the background. As you can see, it is well worth it to ensure you have at least 3 DAG nodes in a DAG just to utilize DAC. But again, in Exchange 2010 SP1, DAC can be utilized with DAGs that contain two nodes.
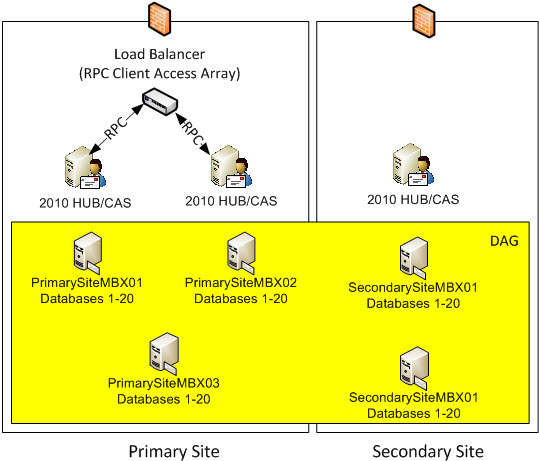
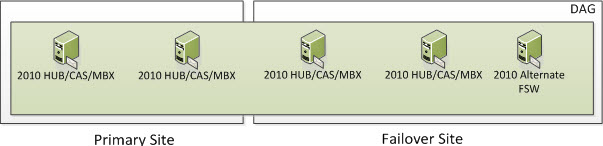
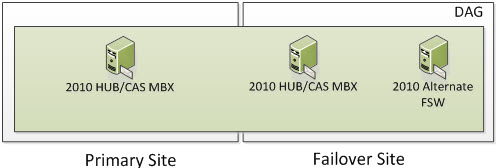
Welcome to Part 3 of Exchange 2010 Site Resilient DAGs and Majority Node Set Clustering. In Part 1, I discussed what Majority Node Set Clustering is and how it works with Exchange Site Resilience when you have one DAG member in a Primary Site and one DAG member in a Failover Site. In Part 2, I discussed how Majority Node Set Clustering works with Exchange Site Resileince when you have two DAG members in a Primary Site and one DAG member in a Failover Site. In this Part, I will show an example of how Majority Node Set Clustering works with Exchange Site Resilience when you have two DAG members in a Primary Site and two DAG members in a Failover Site.
Each of these examples will show DAG Models with a Primary Site and a Failover Site.
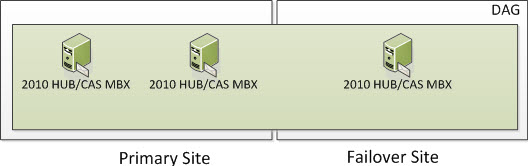
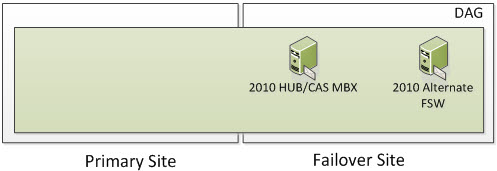
4 Node DAG (Two in Primary and Two in Failover)
In the following screenshot, we have 4 Servers. Four are Exchange 2010 Multi-Role Servers; two in the Primary Site and two in the Failover Site. The Cluster Service is running only on the four Exchange Multi-Role Servers. More specifically, it would run on the Exchange 2010 Servers that have the Mailbox Server Role. When Exchange 2010 utilizes an even number of Nodes, it utilizes Node Majority with File Share Witness. If you have dedicated HUB and/or HUB/CAS Servers, you can place the File Share Witness on those Servers. However, the File Share Witness cannot be placed on the Mailbox Server Role.
So now we have our five Servers; four of them being Exchange. This means we have five voters. Four of the Mailbox Servers that are running the cluster service are voters and the File Share Witness is a witness that the voters use to maintain cluster quorum. So the question is, how many voters/servers/cluster objects can I lose? Well if you read the section on Majority Node Set (which you have to understand), you know the formula is (number of nodes /2) + 1. This means we have (4 Exchange Servers / 2) = 2 + 1 = 3. This means that 3 cluster objects must always be online for your Exchange Cluster to remain operational.
But now let’s say one or two of your Exchange Servers go offline. Well, you still have at least three cluster objects online. This means your cluster will be still be operational. If all users/services were utilizing the Primary Site, then everything continues to remain completely operational. If you were sending SMTP to the one of the servers in the Failover Site or users were for some reason connecting to the Failover Site, they will need to be pointed to another Exchange Server that is operational in the Primary Site or the Failover Site. This of course depends on whether the user databases are being replicated from a mailbox database failover standpoint.
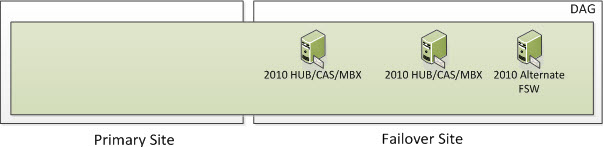
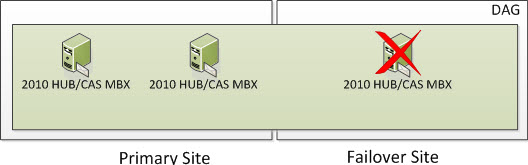
But what happens if you lose a third node in which all DAG members in the Failover Site go offline including the FSW? Well, based on the formula above we need to ensure we have 3 cluster objects operational at all times. At this time, the entire cluster goes offline. You need to go through steps provided in the site switchover process but in this case, you would be activating the Primary Site and specify a new Alternative File Share Witness Server that exists in the Primary Site so you can active the Exchange 2010 Server in the Primary Site. The DAG will actively use the File Share Witness since there will be 2 Exchange DAG Members remaining which is an even number of nodes. And again, when you have an even number of nodes, you will use a File Share Witness.
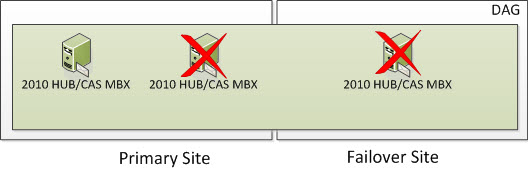
But what happens if you lose two nodes in the Primary Site as well as the FSW due to something such as Power Failure or a Natural Disaster? Well, based on the formula above we need to ensure we have 3 cluster objects operational at all times. At this time, the entire cluster goes offline. You need to go through steps provided in the site switchover process but in this case, you would be activating the Failover Site and specify a new Alternative File Share Witness Server that exists (or will exist) in the Failover Site so you can activate the Exchange 2010 Servers in the Failover Site. The DAG will actively use the Alternate File Share Witness since there will be 2 Exchange DAG Members remaining which is an even number of nodes. And again, when you have an even number of nodes, you will use a File Share Witness.
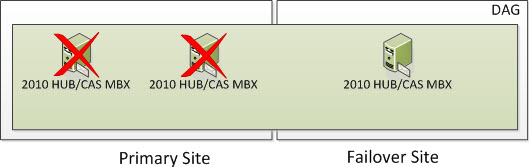
Once the Datacenter Switchover has occurred, you will be in a state that looks as such. An Alternate File Share Witness is not for redundancy for your 2010 FSW that was in your Primary Site. It’s used only during a Datacenter Switchover which is a manual process.
Once your Primary Site becomes operational, you will re-add the two Primary DAG Servers to the existing DAG which will still be using the 2010 Alternate FSW Server in the Failover Site and you will now be switched into a Node Majority with File Share Witness Cluster instead of just Node Majority. Remember I said with an odd number of DAG Servers, you will be in Majority Node Witness and with an even number, the Cluster will automatically switch itself to Node Majority with File Share Witness? You will now be in a state that looks as such.
Part of the Failback Process would be to switch back to the old FSW Server in the Primary Site. Once done, you will be back into your original operational state.
As you can see with how this works, the question that may arise is where to put your FSW? Well, it should be in the Primary Site with the most users or the site that has the most important users. With that in mind, I bet another question arises? Well, why with the most users or the most important users? Because some environments may want to use the above with an Active/Active Model instead of an Active/Passive. Some databases may be activated in both sites. But, with that, if the WAN link goes down, the Exchange 2010 Server in the Failover Site loses quorum since it can’t contact at least 2 other cluster objects. Again, you must have three cluster objects online. This also means that each cluster object must be able to see two other cluster objects. Because of that, the Exchange 2010 Server will go completely offline.
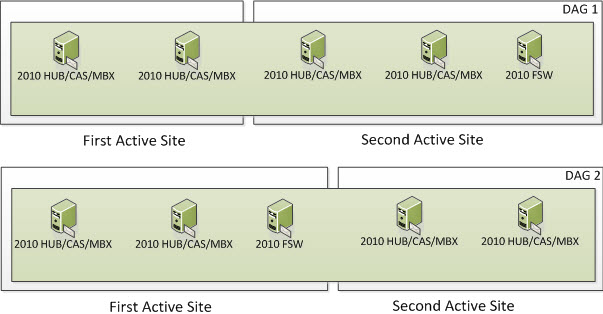
To survive this, you really must use 2 different DAGs. One DAG where the FSW is in the First Site and a second DAG where its FSW is in the Second Site. In my example, users that live in the First Active Site would primarily be using the Exchange 2010 DAG Members in the First Active Site which would be on DAG 2. Users that live in the Second Active Site would primarily be using the Exchange 2010 DAG Members in the Second Active Site which would be on DAG 1. This way, if anything happens with the WAN link, users in the First Active Site would still be operational as the FSW for their DAG is in the First Active Site and DAG 2 would maintain Quorum. Users in the Second Active Site would still be operational as the FSW for their DAG is in the Second Active Site and DAG 1 would maintain Quorum.
Note: This would require twice the amount of servers since a DAG Member cannot be a part of more than one DAG. As shown below, each visual representation below of a 2010 HUB/CAS/MBX is a separate server.
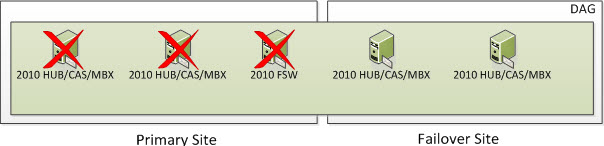
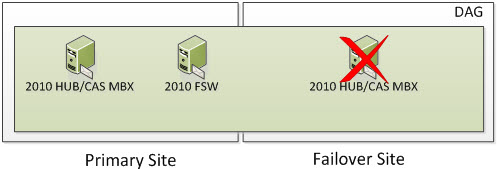
Welcome to Part 2 of Exchange 2010 Site Resilient DAGs and Majority Node Set Clustering. In Part 1, I discussed what Majority Node Set Clustering is and how it works with Exchange Site Resilience when you have one DAG member in a Primary Site and one DAG member in a Failover Site. In this Part, I will show an example of how Majority Node Set Clustering works with Exchange Site Resilience when you have two DAG members in a Primary Site and one DAG member in a Failover Site.
In Part 1, I showed a Real World example when you have one Exchange DAG member in the Primary Site and one Exchange DAG member in the Failover Site. In this Part, I am showing a Real World example when you have two Exchange DAG members in the Primary Site and one Exchange DAG member in the Failover Site.
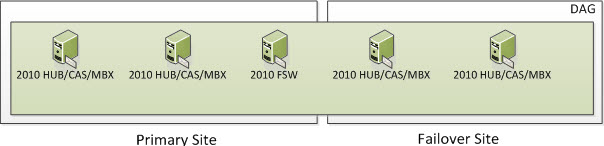
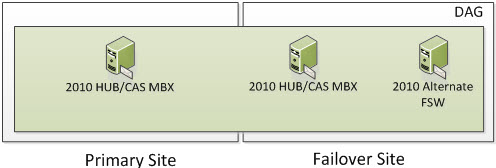
3 Node DAG (Two in Primary and One in Failover)
In the following screenshot, we have 3 Servers. Two are Exchange 2010 Multi-Role Servers; one in the Primary Site and one on the Failover Site. The Cluster Service is running on all three Exchange Multi-Role Servers. More specifically, it would run on the Exchange 2010 Servers that have the Mailbox Server Role. When Exchange 2010 utilizes an even number of Nodes, it utilizes Node Majority with File Share Witness. Because we have an odd number of Nodes, we are utilizing Node Majority and will not utilize a File Share Witness.
So now we have our three Servers; all three of them being Exchange. This means we have three voters and do not need a File Share Witness as we have a third node. So the question is, how many voters/servers/cluster objects can I lose? Well if you read the section on Majority Node Set (which you have to understand), you know the formula is (number of nodes /2) + 1. This means we have (3 Exchange Servers / 2) rounded down = 1 + 1 = 2. This means that 2 cluster objects must always be online for your Exchange Cluster to remain operational just like if we were utilizing 2 DAG members with a File Share Witness.
But now let’s say one of your Exchange Servers go offline. Well, you still have at least two cluster objects online. This means your cluster will be still be operational. If all users/services were utilizing the Primary Site, then everything continues to remain completely operational. If you were sending SMTP to the Failover Site or users were for some reason connecting to the Failover Site, they will need to be pointed to the Exchange Server in the Primary Site.
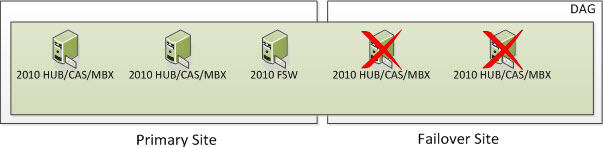
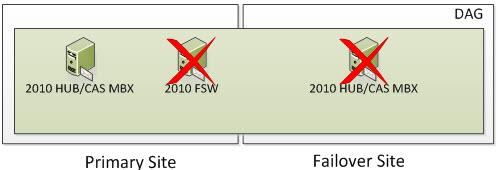
But what happens if you lose a second node? Well, based on the formula above we need to ensure we have 2 cluster objects operational at all times. At this time, the entire cluster goes offline. You need to go through steps provided in the site switchover process but in this case, you would be activating the Primary Site and specify a new Alternative File Share Witness Server that exists in the Primary Site so you can active the Exchange 2010 Server in the Primary Site. The DAG won’t actively use the File Share Witness but you should specify it anyways because part of the Failback process is re-adding the Primary Site Servers back to the DAG once they become operational. And once you re-add the second DAG node, you now have two DAG members in the DAG which will want to switch the DAG Cluster into a Node Majority with File Share Witness which is why you need to still specify a File Share Witness.
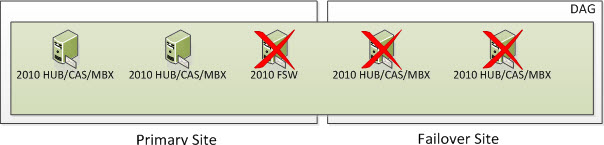
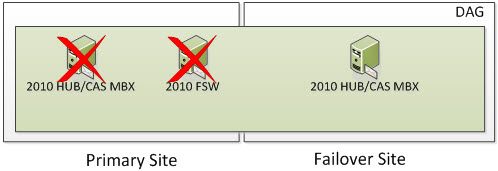
But what happens if you lose two nodes in the Primary Site? Well, based on the formula above we need to ensure we have 2 cluster objects operational at all times. At this time, the entire cluster goes offline. You need to go through steps provided in the site switchover process but in this case, you would be activating the Failover Site and specify a new Alternative File Share Witness Server that exists (or will exist) in the Failover Site so you can activate the Exchange 2010 Server in the Primary Site. The DAG won’t actively use the File Share Witness but you should specify it anyways because part of the Failback process is re-adding the Primary Site Servers back to the DAG once they become operational.
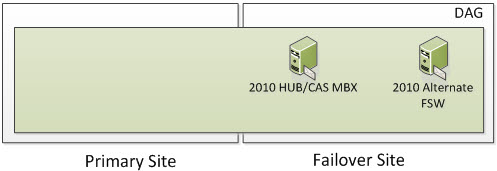
Once the Datacenter Switchover has occurred, you will be in a state that looks as such. An Alternate File Share Witness is not for redundancy for your 2010 FSW that was in your Primary Site. It’s used only during a Datacenter Switchover which is a manual process.
Once your Primary Site becomes operational, you will re-add the Primary DAG Server to the existing DAG which will still be using the 2010 Alternate FSW Server in the Failover Site and you will now be switched into a Node Majority with File Share Witness Cluster instead of just Node Majority. Remember I said with an odd number of DAG Servers, you will be in Majority Node Witness and with an even number, the Cluster will automatically switch itself to Node Majority with File Share Witness? You will now be in a state that looks as such.
Part of the Failback Process would be to switch to a FSW Server in the Primary Site. Once done, you will be back into your original operational state.
Now the final step of the Failback Process would be to re-add your final remaining DAG Member in the Primary Site. Once done, your cluster will switch back into a Node Majority Cluster and will no longer be utilizing the FSW.
As you can see with how this works, the question that may arise is where to put your the majority of your Exchange DAG Members? Well, it should be in the Primary Site with the most users or the site that has the most important users. With that in mind, I bet another question arises? Well, why with the most users or the most important users? Because some environments may want to use the above with an Active/Active Model instead of an Active/Passive. Some databases may be activated in both sites. But, with that, if the WAN link goes down, the Exchange 2010 Server in the Failover Site loses quorum since it can’t contact at least 1 other cluster object. Again, you must have two cluster objects online. This also means that each cluster object must be able to see one other cluster object. Because of that, the Exchange 2010 Server will go completely offline.
To survive this, you really must use 2 different DAGs. One DAG where the majority of your Exchange 2010 DAG Members is in the First Site and a second DAG where the majority of the Exchange 2010 DAG Members is in the Second Site. Users that live in the First Active Site would primarily be using the Exchange 2010 DAG Members in the First Active Site. Users that live in the Second Active Site would primarily be using the Exchange 2010 DAG Members in the Second Active Site. This way, if anything happens with the WAN link, users in the First Active Site would still be operational as the majority of its Exchange 2010 DAG Members for their DAG is in the First Active Site and DAG 1 would maintain Qourum. Users in the Second Active Site would still be operational as the majority of its Exchange 2010 DAG Members for their DAG is in the Second Active Site and DAG 2 would maintain Quorum.
Note: This would require twice the amount of servers since a DAG Member cannot be a part of more than one DAG. As shown below, each visual representation below of a 2010 HUB/CAS/MBX is a separate server.
I’ve talked about this topic in some of my other articles but wanted to create an article that talks specifically about this model and show several different examples in a Database Availability Group (DAG)’s tolerance for node and File Share Witness (FSW) failure. Many people don’t properly understand how the Majority Node Set Clustering Model works. In my article here, I talk about Database Activation Coordination Mode and have a section on Majority Node Set. In this article, I want to visibly show show some real world examples on how the Majority Node Set Clustering Model works. This will be a multi-part article and each Part will have its own example.
Majority Node Set is a Windows Clustering Model such as the Shared Quorum Model, but different. Both Exchange 2007 and Exchange 2010 Clusters use Majority Node Set Clustering (MNS). This means that 50% of your votes (server votes and/or 1 file share witness) need to be up and running. The proper formula for this is (n / 2) + 1 where n is the number of DAG nodes within the DAG. With DAGs, if you have an odd number of DAG nodes in the same DAG (Cluster), you have an odd number of votes so you don’t have a witness. If you have an even number of DAGs nodes, you will have a file share witness in case half of your nodes go down, you have a witness who will act as that extra +1 number.
So let’s go through an example. Let’s say we have 3 servers. This means that we need (number of nodes which is 3 / 2) + 1 which equals 2 as you round down since you can’t have half a server/witness. This means that at any given time, we need 2 of our nodes to be online which means we can sustain only 1 (either a server or a file share witness) failure in our DAG. Now let’s say we have 4 servers. This means that we need (number of nodes which is 4 / 2) + 1 which equals 3. This means at any given time, we need 3 of our servers/witness to be online which means we can sustain 2 server failures or 1 server failure and 1 witness failure.
Real World Examples
Each of these examples will show DAG Models with a Primary Site and a Failover Site.
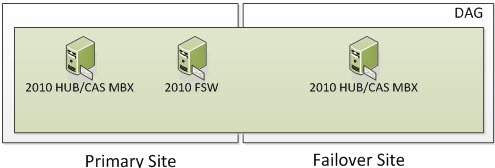
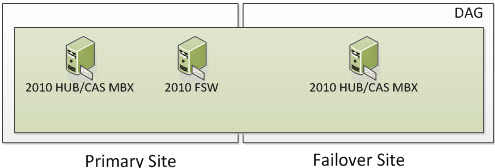
2 Node DAG (One in Primary and One in Failover)
In the following screenshot, we have 3 Servers. Two are Exchange 2010 Multi-Role Servers; one in the Primary Site and one on the Failover Site. The Cluster Service is running only on the two Exchange Multi-Role Servers. More specifically, it would run on the Exchange 2010 Servers that have the Mailbox Server Role. When Exchange 2010 utilizes an even number of Nodes, it utilizes Node Majority with File Share Witness. If you have dedicated HUB and/or HUB/CAS Servers, you can place the File Share Witness on those Servers. However, the File Share Witness cannot be placed on the Mailbox Server Role.
So now we have our three Servers; two of them being Exchange. This means we have two voters and a File Share Witness. Two of the Mailbox Servers that are running the cluster service are voters and the File Share Witness is just a witness that the voters use to determine cluster majority. So the question is, how many voters/servers can I lose? Well if you read the section on Majority Node Set (which you have to understand), you know the formula is (number of nodes /2) + 1. This means we have (2 Exchange Servers / 2) = 1 + 1 = 2. This means that 2 cluster objects must always be online for your Exchange Cluster to remain operational.
But now let’s say one of your Exchange Servers go offline. Well, you still have at least two cluster objects online. This means your cluster will be still be operational. If all users/services were utilizing the Primary Site, then everything continues to remain completely operational. If you were sending SMTP to the Failover Site or users were for some reason connecting to the Failover Site, they will need to be pointed to the Exchange Server in the Primary Site.
But what happens if you lose a second node? Well, based on the formula above we need to ensure we have 2 cluster objects operational at all times. At this time, the entire cluster goes offline. You need to go through steps provided in the site switchover process but in this case, you would be activating the Primary Site and specify a new Alternative File Share Witness Server that exists in the Primary Site so you can active the Exchange 2010 Server in the Primary Site. The DAG won’t actively use the File Share Witness but you should specify it anyways because part of the Failback process is re-adding the Primary Site Servers back to the DAG once they become operational.
But what happens if you lose two nodes in the Primary Site? Well, based on the formula above we need to ensure we have 2 cluster objects operational at all times. At this time, the entire cluster goes offline. You need to go through steps provided in the site switchover process but in this case, you would be activating the Failover Site and specify a new Alternative File Share Witness Server that exists (or will exist) in the Failover Site so you can activate the Exchange 2010 Server in the Primary Site. The DAG won’t actively use the File Share Witness but you should specify it anyways because part of the Failback process is re-adding the Primary Site Servers back to the DAG once they become operational.
Once the Datacenter Switchover has occurred, you will be in a state that looks as such. An Alternate File Share Witness is not for redundancy for your 2010 FSW that was in your Primary Site. It’s used only during a Datacenter Switchover which is a manual process.
Once your Primary Site becomes operational, you will re-add the Primary DAG Server to the existing DAG which will still be using the 2010 Alternate FSW Server in the Failover Site and you will now be switched into a Node Majority with File Share Witness Cluster instead of just Node Majority. Remember I said with an odd number of DAG Servers, you will be in Node Majority and with an even number, the Cluster will automatically switch itself to Node Majority with File Share Witness? You will now be in a state that looks as such.
Part of the Failback Process would be to switch back to the old FSW Server in the Primary Site. Once done, you will be back into your original operational state.
As you can see with how this works, the question that may arise is where to put your FSW? Well, it should be in the Primary Site with the most users or the site that has the most important users. With that in mind, I bet another question arises? Well, why with the most users or the most important users? Because some environments may want to use the above with an Active/Active Model instead of an Active/Passive. Some databases may be activated in both sites. But, with that, if the WAN link goes down, the Exchange 2010 Server in the Failover Site loses quorum since it can’t contact at least 1 other voter. Again, you must have two voters online. This also means that each voter must be able to see one other voter. Because of that, the Exchange 2010 Server will go completely offline.
To survive this, you really must use 2 different DAGs. One DAG where the FSW is in the First Site and a second DAG where its FSW is in the Second Site. Users that live in the First Active Site would primarily be using the Exchange 2010 DAG Members in the First Active Site. Users that live in the Second Active Site would primarily be using the Exchange 2010 DAG Members in the Second Active Site. This way, if anything happens with the WAN link, users in the First Active Site would still be operational as the FSW for their DAG is in the First Active Site and DAG 1 would maintain Qourum. Users in the Second Active Site would still be operational as the FSW for their DAG is in the Second Active Site and DAG 2 would maintain Quorum.
Note: This would require twice the amount of servers since a DAG Member cannot be a part of more than one DAG. As shown below, each visual representation below of a 2010 HUB/CAS/MBX is a separate server.
In part three of this multi-part article, we created the log and database LUNs, changed the path for the logs and databases, created the DAG, and added the servers to the DAG.
In this fourth part of this multi-part article uncovering Exchange 2010 Database Availability Groups (DAGs), I am going to show you how to configure miscellaneous interesting DAG settings and perform the most typical operational tasks.
Fasten your seatbelt and let us get moving!
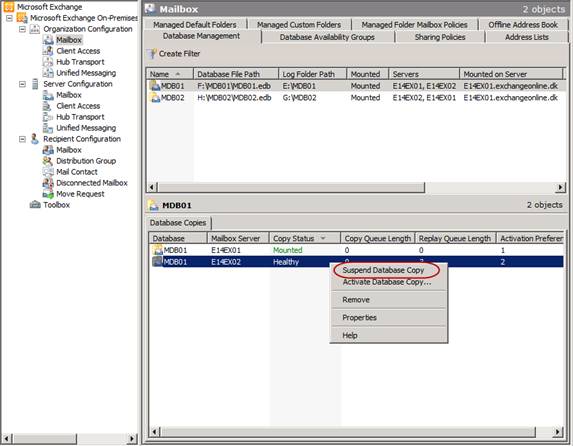
Suspending and Resuming Database Copies
In situations where you have a planned outage/maintenance window or if you perhaps need to seed a database, the first step is to suspend replication for the involved database(s). This can be done both via the Exchange Management Console (EMC) and the Exchange Management Shell (EMS). To do so via the EMC, you simply right-click on the respective database copy/copies and select suspend in the context menu.
Figure 1: Suspending a Database copy
To do the same via the EMS, you can use the following command:
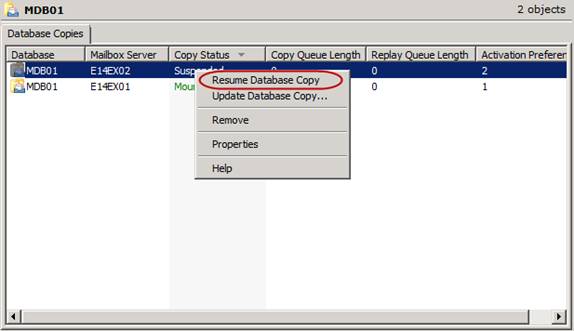
In order to resume a database copy using the EMC, you just right-click on it again and choose Resume Database Copy.
Figure 2: Resuming a Database Copy
If you rather want to resume it using the EMS, run the following command:
Resume-MailboxDatabaseCopy –Identity MDB02E14EX02
Moving the Active Database Copy to another DAG Member (aka Switchover)
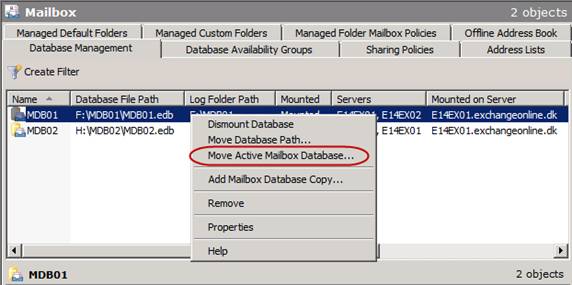
When you have a planned outage and need to take a DAG member that holds one or more active database copies down for maintenance, it’s considered best practice to manually move any active database copies (aka performing a switchover) to another DAG member in the DAG. To move an active database copy to another DAG member using the EMC is accomplished by right-clicking on the respective database(s) and selecting Move Active Mailbox Database in the context menu as shown in Figure 3.
Figure 3: Activating a Database Copy
This brings up the Activate a Database Copy wizard (Figure 4).
Figure 4: Activate Database Copy wizard
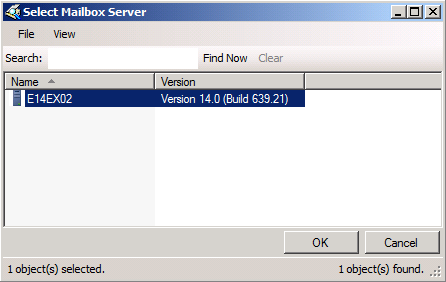
Here we can see the name of the database and on which DAG member it currently is mounted. To move the database copy to another DAG member, click Browse.
Figure 5: Selecting the server holding the database copy to be activated
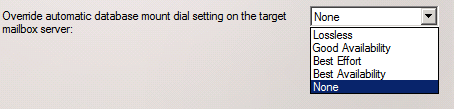
When you have selected the DAG member on which the databse copy should be activated, click OK. Then decide if you want to change the database mount dial settings on the target mailbox server. As you can see in Figure 6 its set toNone (change nothing) by default. If you want to change the current setting (set to Best Availability by default) instead choose Lossless, Best Effort, or Best Availability.
Figure 6: Automatic database mount dial settings
Here’s a description of each of the available database mount dial settings:
Lossless: (when selecting Lossless the database will not mount automatically until all logs generated on the active database copy has been copied to the passive database copy)
Good Availability: (when selecting Good Availability, the database will mount automatically as long as you have a copy queue length less than or equal to 6. If the copy queue holds more than 6 log files, the database will not mount)
Best Effort: (with Best Effort the database will mount no matter the copy queue length. Be careful with this setting as you could loose a lot of mailbox data!)
Best Availability: (with Best Availbility the database will mount automatically as long as the copy queue length is less than or equal to 12. If the copy queue length is more than 12, the database will not be able to mount)
Unless there’s a specific reason to chose another database mount dial override than the setting currently configured, leave this option at None. When you are ready to activate the database copy in the target mailbox server specified, click Move.
To activiate a database copy using the EMS, we can use the following command:
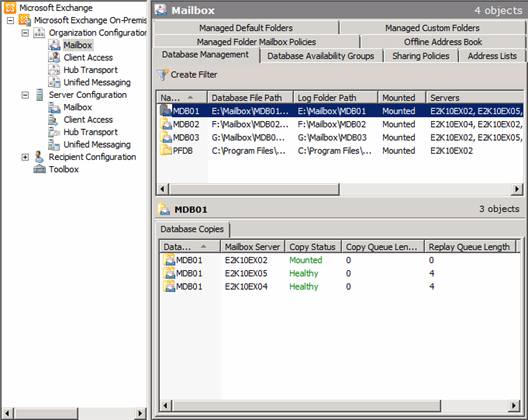
There may be times where you need to seed a database copy for one reason or the other. This can both be done via the Exchange Management Console (EMC) and the Exchange Management Shell (EMS). Let us take a look at how to accomplish this via the EMC.
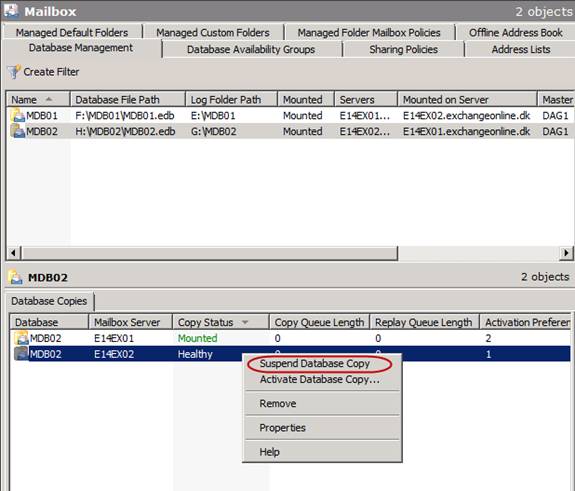
If it is not already the case, the first thing we must do is to suspend replication for the passive database copy we want to seed.
Figure 7: Suspending the Database Copy
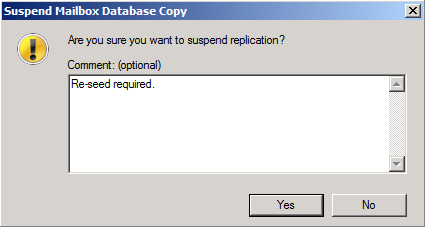
You will now be presented with a dialog box where you can enter a comment on why replication for the database copy is being suspended.
Figure 8: Dialog box for optional comment
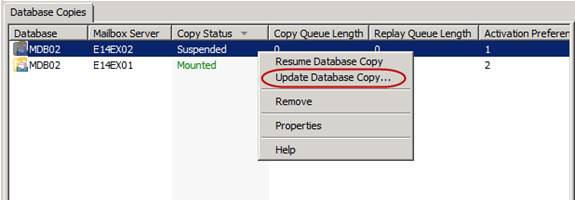
When suspended, right-click on the database copy once again and select Update Database Copy.
Figure 9: Selecting update Database copy in the context menu
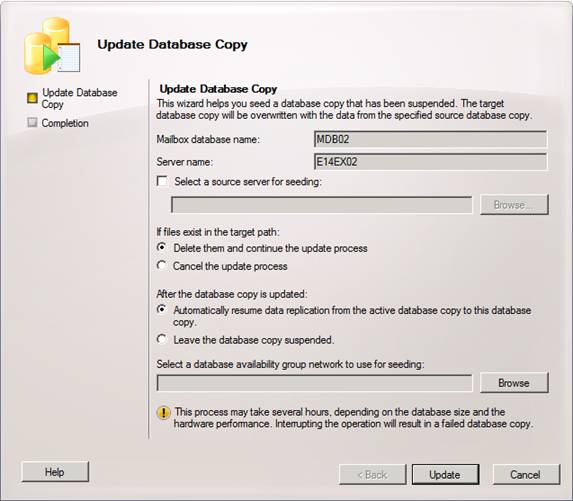
The Update Database Copy wizard will now appear (Figure 10).
Figure 10: Update database copy wizard
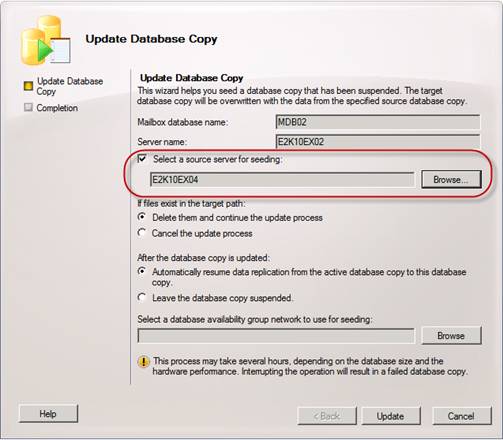
As you can see we have several options in this wizard. We have the option of specifying the source server that should be used for seeding. This is a really cool feature since you are no longer limited to seeding from an active database copy as was the case in with Exchange 2007 LCR/CCR/SCR.
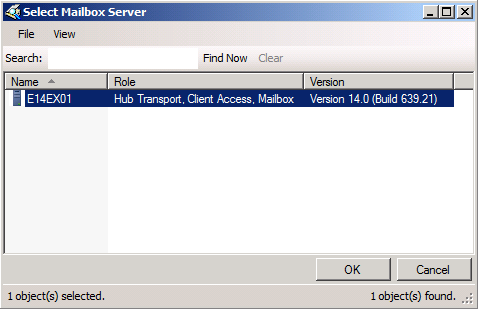
Figure 11: Selecting source seeding server
We can also choose the behavior when files exist in the target path. In addition, we can specify whether replication to this database copy should be resumes or whether it should be leaved suspended.
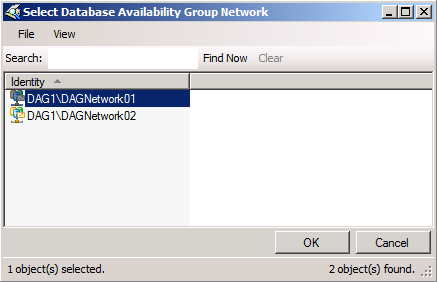
Lastly, we can select which DAG network should be used to seed the database copy. Again a great feature, which although it was an option in Exchange 2007 SP1, was very cumbersome.
Figure 12: Selecting DAG network used for seeding database copy
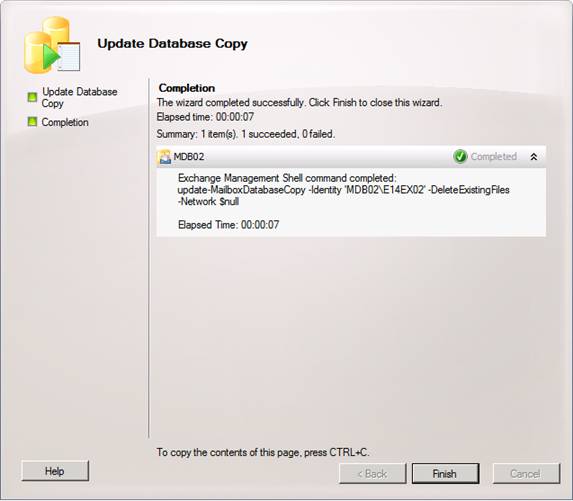
When you have chosen your settings, click Update in order to seed the database copy. When the seeding has completed, click Finish.
Figure 13: Seeding process completed successfully
If you rather want to use the EMS to seed a database copy, the above could be accomplished by first suspending replication with:
Figure 14: Suspending a database copy via the Exchange Management Shell
Then run the following command to re-seed the database copy:
Update-MailboxDatabaseCopy -Identity MDB02E14EX02
Figure 15: Seeding a database copy via the Exchange Management Shell
Changing the Log file Replication Port
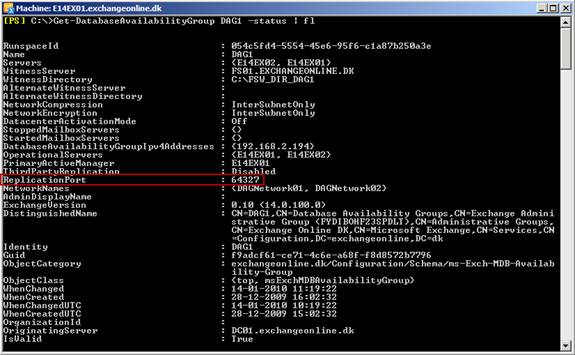
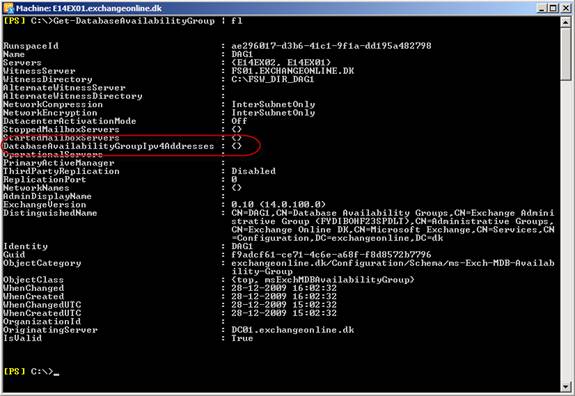
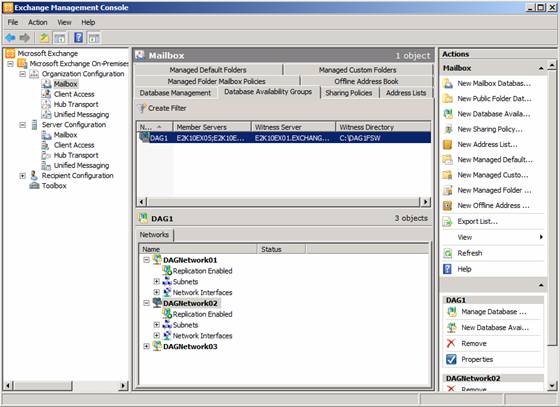
In Exchange 2007, the Microsoft Exchange Replication Service copies log files to the passive database copy (LCR), passive cluster node (CCR) or SCR target over Server Message Block (SMB). With DAGs in Exchange 2010, the asynchronous replication technology no longer relies on SMB. Instead, Exchange 2010 uses TCP/IP for log file copying and seeding and, even better; it provides the option of specifying which port you want to use for log file replication. By default, DAG uses TCP port 64327, but you are free to specify whatever port you want to use. To see the current port used, you must use the Get-AvailabilityGroup cmdlet with the –Status parameter. To see the port used in our lab environment, use:
Get-DatabaseAvailabilityGroup DAG1 –Status | fl
Figure 16: Checking Replication port settings for a DAG
To change the port used we must use Exchange Management Shell (EMS) as this option isn’t included in the Exchange Management Console (EMC). Since this setting is configured per DAG, we must use the Set-DatabaseAvailabilityGroup cmdlet.
For instance to change the port for the DAG in our lab to TCP port 7580, we must use the following command:
Figure 17: Checking new Replication port settings for a DAG
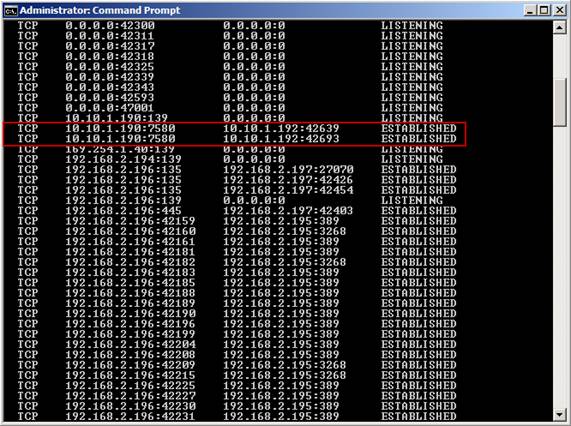
Now when updating a database copy, we can see that TCP/7580 is used (below I ran Netstat –an while the database copy were updated.
Figure 18: Checking the new replication port is used (by running Netstat -an)
Log file Network Compression
With DAGs in Exchange 2010, we can enable or disable compression for seeding and replication activities over one or more networks in a DAG. This is a property of the DAG itself, not a DAG network. The default setting isInterSubnetOnly (which means compression is used when replication occur across subnets) as shown in Figure 19.
Figure 19: Checking Network Compression settings for a DAG
The available values are:
Disabled (disabled on all networks)
Enabled (enabled on all networks)
InterSubnetOnly (enabled for inter-subnet communication only)
SeedOnly (enabled only for seeding)
If we for instance want to enable network compression for log file copying and seeding on all networks in a DAG in our lab environment, we would use the following command:
Figure 20: Checking new Network Compression settings for a DAG
With compression enabled for log file seeding and replication, you can expect around 30% compression ratio. As you can see, there’s really no reason why you should disable network compression unless you for instance use a 3rd party WAN/network optimizer that doesn’t support DAG network compression.
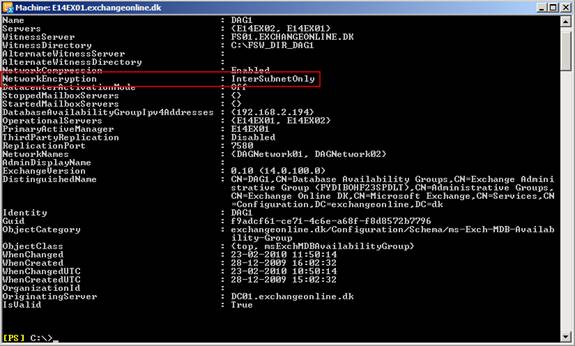
Log file Network Encryption
With DAGs in Exchange 2010 there’s now native support for encryption of log file seeding and replication activities. In Exchange 2007 log files are copied over an unencrypted channel unless IPsec has been configured. DAG leverages the encryption capabilities of Windows Server 2008/R2, that is DAG uses Kerberos authentication between each DAG member. Network encryption is a property of the DAG itself, not the DAG network. Available settings for the network encryption property are:
Disabled (network encryption not in use),
Enabled (network encryption enabled for seeding and replication on all networks associated with a DAG),
InterSubnetOnly (the default setting meaning network encryption is used across subnets)
SeedOnly (network encryption in use for seeding on all networks in a DAG).
The default setting is InterSubnetOnly.
Figure 21: Checking Network Encryption settings for a DAG
If you want to change the network encryption settings, you can use the Set-DatabaseAvailabilityGroupcmdlet. For instance, if you wanted to enable encryption for log copying and seeding on all networks, you would use the following command:
Figure 22: Checking new Network Encryptions settings for a DAG
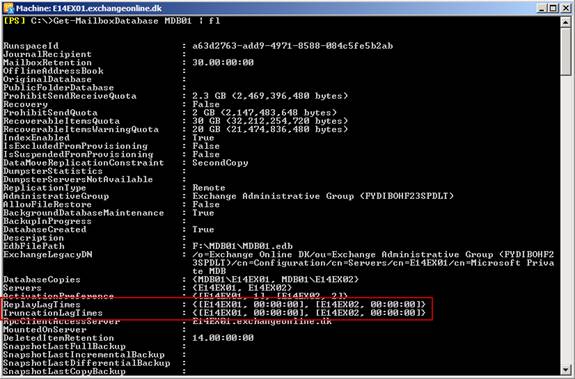
Configuring Replay & Truncation Lag Time
The Standby Continuous Replication (SCR) feature that was introduced with Exchange 2007 SP1 gave us the option of replicating one or more databases from a stand-alone mailbox server, cluster continuous replication (CCR) cluster, or single copy cluster (SCC) to a target stand-alone mailbox server or standby cluster (CCR or SCC failover cluster where only the passive clustered mailbox role has been installed). SCR could both be used for replicating storage groups locally in a datacenter or remotely to servers located in a secondary or backup datacenter.
In addition to being able to replicate data to multiple targets per storage group, SCR also introduced the concept of replay lag time and truncation lag time. With replay lag time you could configure the Microsoft Exchange Replication service to wait for a specified amount of time before log files that had been copied from the SCR source to the SCR target(s) were replayed. The default value for replay lag time was 24 hours and could be configured with a value of up to 7 days (if configured to 0 seconds there were a 50 log files lag time so that a reseed wasn’t require when a lossy failover has occurred). The idea with replay lag time was to have a database from back in time, which could be used to recover if active database copy/copies on the SCR source server(s) were struck by logical corruption. This way to can stop replication before the logical corruption is replicated to the SCR target server(s) and thereby prevent loosing data.
Truncation lag time could be used to specify how long the Microsoft Exchange Replication service should wait before truncating (deleting) the log files that had been copied to the SCR target server (s) and replayed into the copy of the database(s). The maximum allowable setting for truncation lag time is 7 days and the minimum is 0 seconds, which will remove the truncation delay completely. With truncation lag time you could recover from failures that affected the log files on the SCR source server(s).
DAG also supports replay lag time and truncation lag time we know from SCR in Exchange 2007 SP1. They work pretty much the same way although controlled via a new cmdlet (Set-MailboxDatabaseCopy).
These features have been improved a little with Exchange 2010. For instance, the replay lag time option now has a maximum setting of 14 days instead of 7 days as was the case with Exchange 2007 SP1. Also bear in mind that unlike SCR in Exchange 2007 SP1, replay lag time in Exchange 2010 does not have a hard-coded replay lag of 50 log files (even when set to 0 seconds).
As you can see in Figure 23 both replay and truncation lag time are disabled by default.
Figure 23: Default Replay and Truncation Lag time setting for a Mailbox database
The purpose with replay and truncation lag time in Exchange 2010 is pretty much the same as with SCR in Exchange 2007 SP1 that is to protect against database logical corruption and store logical corruption. What’s interesting and new with Exchange 2010 is you now can use lagged database copies in combination with legal hold etc.
I won’t dive further into lagged database copies in this multi-part article. Instead I’ll cover this topic in a future articles here on MSExchange.org.
Blocking a Database Copy from being activated
There are situations where you might want to block a passive database copy (or even server) in a DAG from being changed activated (changed to the active database copy). Good thing is the Exchange Product group thought about this kind of scenario. You can do exactly that using a so called activation policy. It’s not possible to use the EMC to set this, but using the EMS, you can use the Suspend-MailboxDatabaseCopy cmdlet for this purpose. Yes correct, this cmdlet is typically used for suspending replication for a database copy, but when run with a special ActivationOnlyparameter, you can block a database copy from being changed to the active database copy during a failover. For instance, if we want to block MDB01 on E14EX02 from ever being activated during a failover, we can use the following command:
Figure 24: Blocking a database copy from being activated
Notice this does not suspend replication for the database copy and thereby result in, an over time, huge copy queue. Only the database copy is being block from activation.
Figure 25: Replication not suspended when using Suspend-MailboxDatabaseCopy with the ActivationOnly parameter
When this cmdlet is run with the ActivationOnly parameter, the database copy cannot be activated until the following command is run:
Resume-MailboxDatabaseCopy –Identity MDB01E14EX02
Figure 26: Unblocking a database copy from being activated
Ok so what if I wish to block all databases on a DAG member server? Will I then need to run the above command on all database copies on the particular server? Luckily not. We have a similar command that works on the server level. If oyu want to block a DAG member instead use the Set-MailboxServer with the DatabaseCopyAutoActivationPolicy Blocked parameter.
For instance if I wanted to block DAG member E14EX02 from having database copies activated, I would use the following command:
Figure 28: unblocking a DAG member from being activated
There’s also an “IntrasiteOnly” option which allows database copies to be activated in the same Active Directory site.
Alright, we have reached the end of part four as well as the end of this multi-part article that hopefully helped you get a better idea of how to deploy DAGs as well as customize miscellaneous settings related to DAGs.
Fear not though, this was definitely not my last article covering DAGs in some form.
In the second part of this multi-part article uncovering Exchange 2010 Database Availability Groups (DAGs), we prepared the two servers and installed Exchange 2010 on both.
In this article, we will continue where we left off. We will move the databases to the LUNs attached to each server, create the DAG and test that it works as expected.
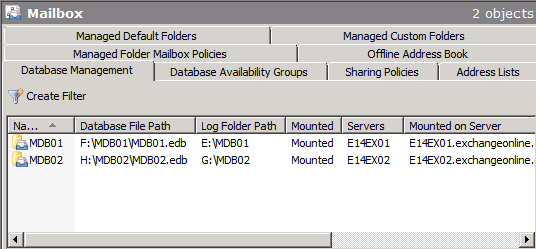
Changing the Exchange Database paths
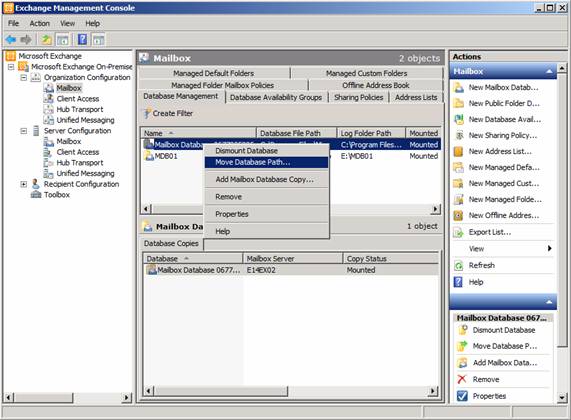
So with Exchange 2010 installed on the servers, the first step is to move and rename each mailbox database. To do so launch the Exchange Management console and navigate to the Mailbox node under the Organization Configuration work center. The first tab here is Database Management, which should be selected. Under this tab, right-click on each mailbox database and select Move Database path in the context menu as shown in Figure 1.
Figure 1: Move Database Path
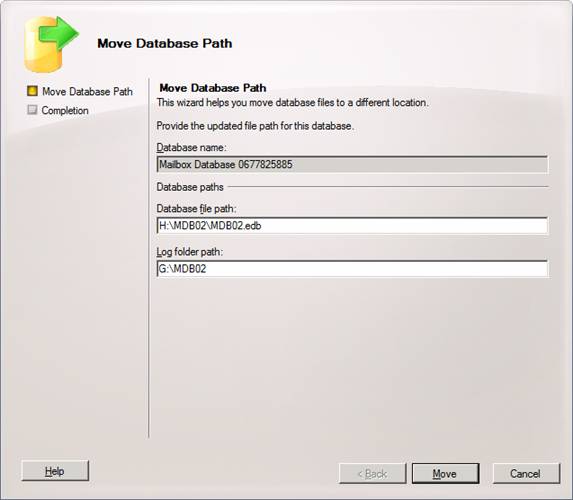
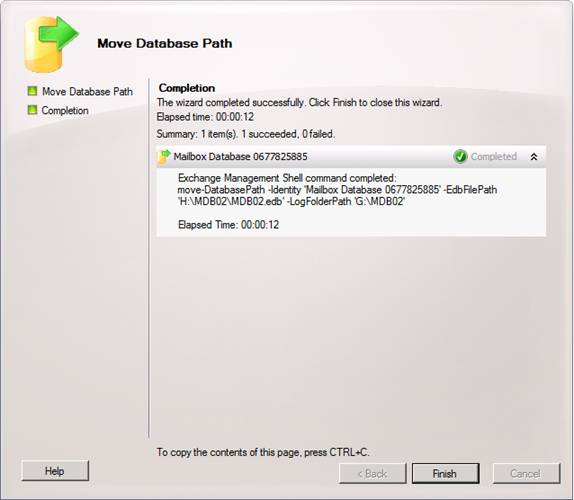
In the Move Database Path wizard, change the path for the database and logs, so that they are placed in the LUNs we created in part 1. I also suggest you change the name of each database to MDB01.edb and MDB02.edb as shown inFigure 2.
When done, click Move.
Figure 2: Changing the path for the database and log files
When they have been moved, click Finish to exit the wizard (Figure 3).
Figure 3: Database and log file path changed successfully
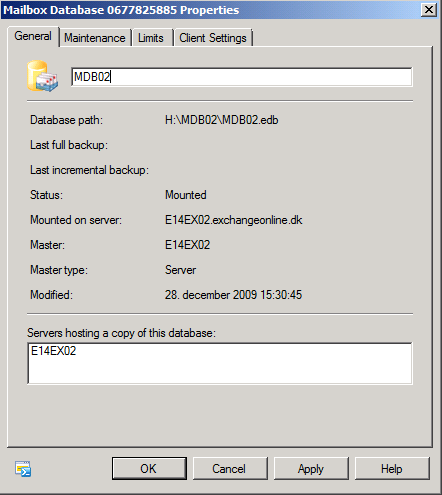
Now right-click on the databases and this time select Properties. Change the name to the name of the edb file itself (in this case to MDB01 and MDB02), and then click OK.
Figure 4: Changing the name of the databases
That was better. This makes it a little easier to specify database names etc. when using the Exchange Management Shell.
Figure 5: Database names and paths changes
Adding the Exchange Trusted Subsystem group to Non-Exchange Servers
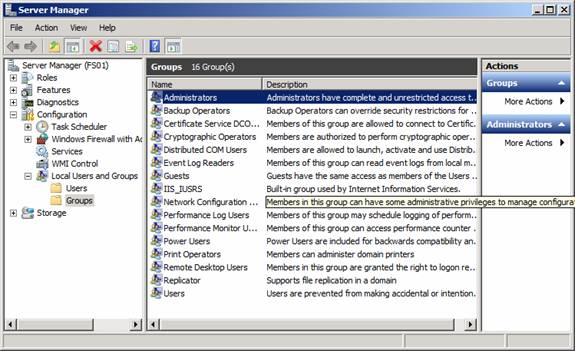
Since we only have two Exchange 2010 servers in our organization, we will not use an Exchange 2010 Hub Transport server (as is the recommended server role to use for the witness server) as the witness server, but instead a traditional Windows Server 2008 R2 File server. This means that we must add the Exchange Trusted Subsystem group to the local administrators group on the file server. To do so, log on to the fileserver and open the Server Manager. ExpandConfiguration > Local Users and Groups, and then open Properties for the Administrators group.
Figure 6: Finding the local administrators group on the Windows Server 2008 R2 file server
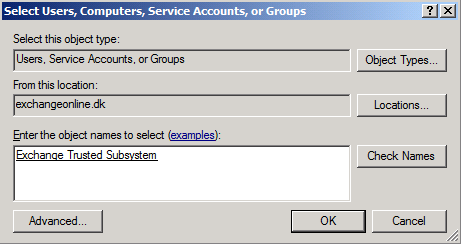
Enter the Exchange Trusted Subsystem group in the text box as shown in Figure 7, then click OK.
Figure 7: Entering the Exchange Trusted Subsystem group
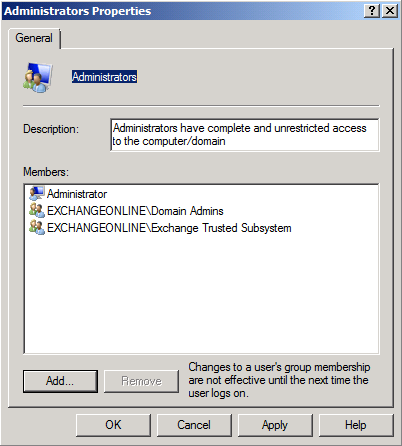
Click OK again.
Figure 8: Property page of the Administrators group
This step is necessary only when using a non-Exchange server as the witness server. By the way, it is not recommended to use a domain controller as the witness server because this way you grant the Exchange Trusted Subsystem group many permissions in the Active Directory domain.
Creating the Database Availability Group
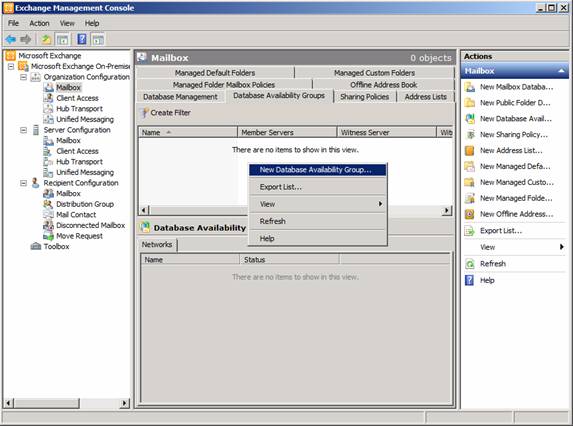
With that we are actually ready to create the DAG itself. This can both be done via the Exchange Management Console or the Exchange Management Shell. In this article we will use the console. So under the Mailbox node, select the Database Availability Group tab, then right-click somewhere in the white area. In the context menu, select New Database Availability Group as shown in Figure 9.
Figure 9: Selecting New Database Availability Group in the context menu
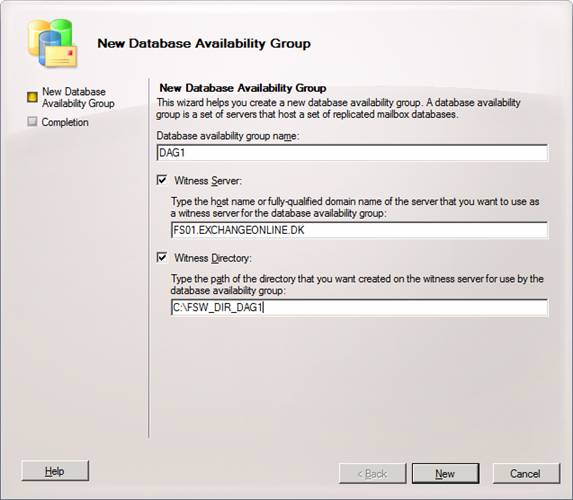
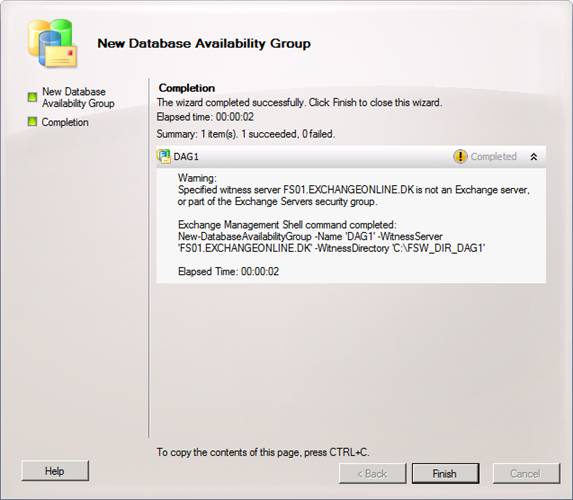
In the Database Availability Group wizard, enter a name for the new DAG. Also, specify the witness server and the witness directory on that server (Figure 10). When you have done so, click New.
Figure 10: Specifying the DAG name as well as witness server and directory
On the Completion page, we get a warning that the specified witness server is not an Exchange Server. You can ignore this.
Click Finish to exit the wizard (Figure 11).
Figure 11: Database Availability Group wizard – Completion page
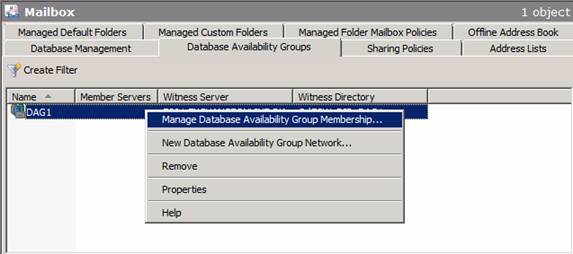
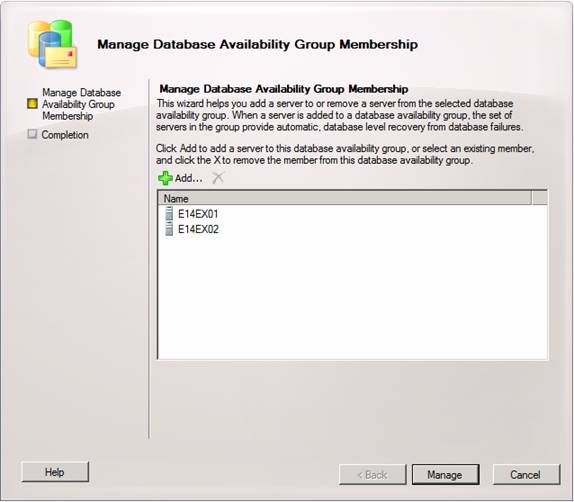
Now that we have created the DAG we can move on and add the two Mailbox servers as member servers. To do so, right-click on the newly created DAG and select Manage Database Availability Group Membership in the context menu as shown in Figure 12 below.
Figure 12: Selecting Manage Database Availability Group Membership
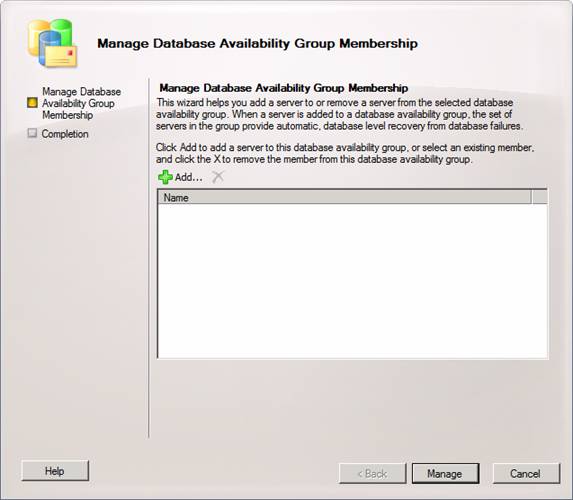
This opens the Manage Database Availability Group Membership wizard, where we click Add.
Figure 13: Manage Database Availability Group Membership wizard
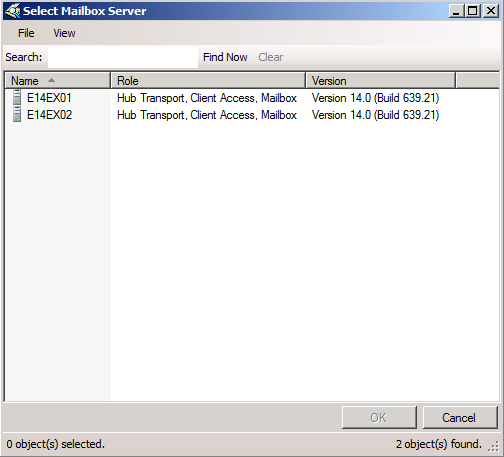
Now select the two servers and click OK.
Figure 14: Adding member servers to the Database Availability Group
Click Manage.
Figure 15: Member servers added to the Database Availability Group
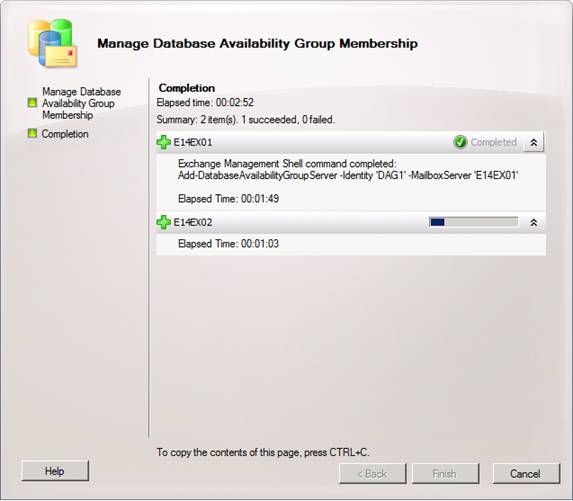
The failover clustering component will now be installed on each server. Then the DAG will be created and configured accordingly. This can take several minutes so have patience.
Figure 16: Waiting for the Manage Database Availability Group Membership wizard to complete
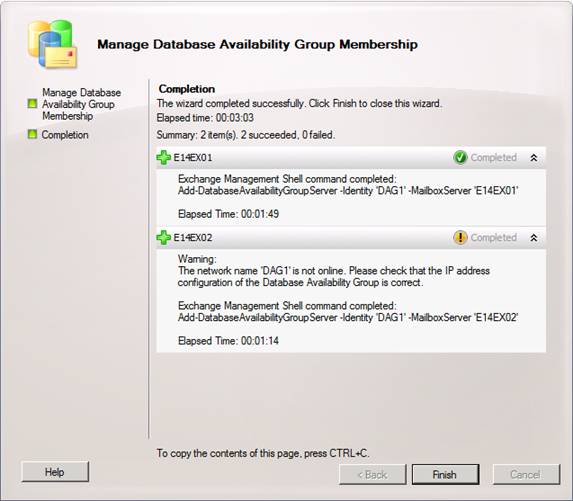
If you do not have DHCP available on the network while the member servers are being added to the DAG, you will get the warning shown in Figure 17.
Note:
DHCP assgined addresses are fully supported for DAG purposes. Actually the Exchange Product group are of the belief most customers will find it a good idea to use a DHCP assigned address for the DAGs. Well, personally I like to give it a static IP address, but that’s just me.
Figure 17: Member servers added to the DAG
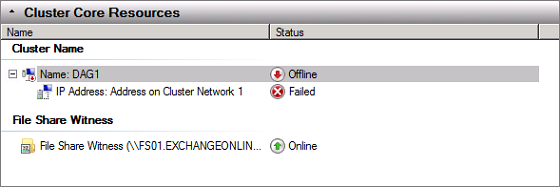
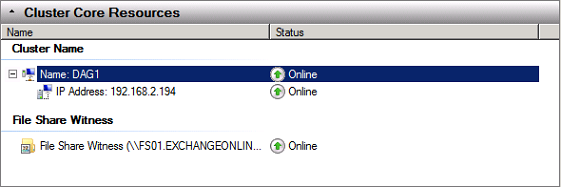
This is fine, we will add a static IP address to the DAG right away. The consecvences of not having an IP address configured for the DAG is that the cluster core resources cannot be brought online as shown in Figure 18.
Figure 18: Cluster core resources offline in Failover Clustering console
One of the things that are missing from the GUI is the option of assigning a static IP address to the DAG, so we need to perform this task via the Exchange Management Shell. So let’s launch the shell and enter the following command:
Get-DatabaseAvailabilityGroup | FL
This shows us, as expected, no IP address is configured for the DAG.
Figure 19: No IP address assigned to the DAG
To assign a static IP address, we need to use the Set-DatabaseAvailabilityGroup cmdlet with theDatabaseAvailabilityGroupIpAddresses parameter:
Now that we have assigned the IP address to the DAG, the cluster core resources can be brought online.
Figure 21: Cluster core resources online in the Failover Clustering console
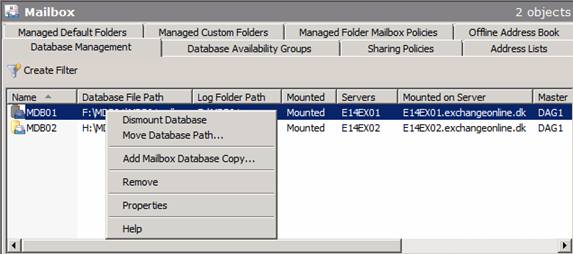
Adding Mailbox Database Copies
Okay it is time to add database copies to the two mailbox databases as a DAG otherwise does not really make any sense. To do so, select the Database Management tab under the Mailbox node in the Organization Configurationworkcenter. Here you right-click on each database and select Add Mailbox Database Copy in the context menu (Figure 22).
Figure 22: Adding database copies to each Mailbox database
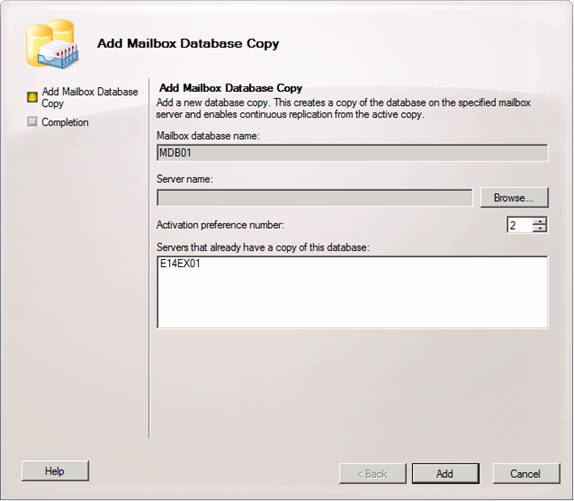
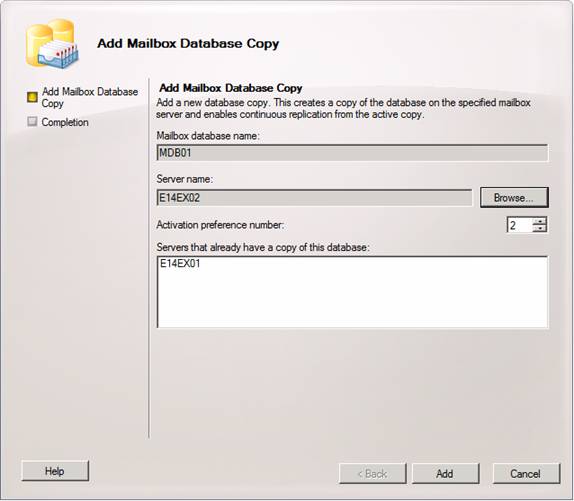
In the Add Mailbox Database Copy wizard, click Browse.
Figure 23: Add Mailbox Database Copy wizard
Now select the mailbox server and click OK.
Figure 24: Selecting the mailbox server that should store a database copy
Back in the Add Mailbox Database Copy wizard wizard, click Add.
Figure 25: Adding the Database copy to the other Mailbox server
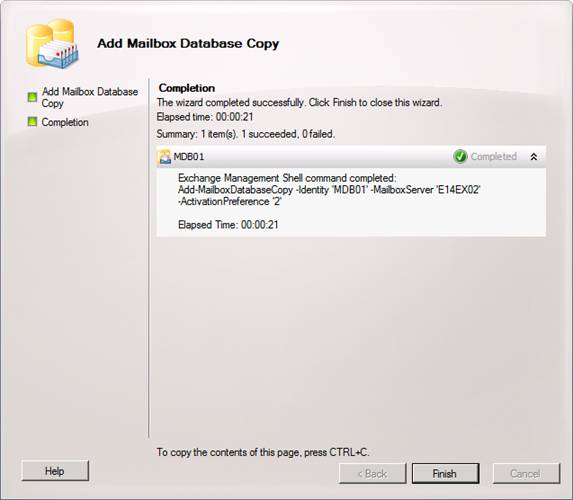
When the wizard has completed successfully, click Finish to exit.
Figure 26: Database copy added with success
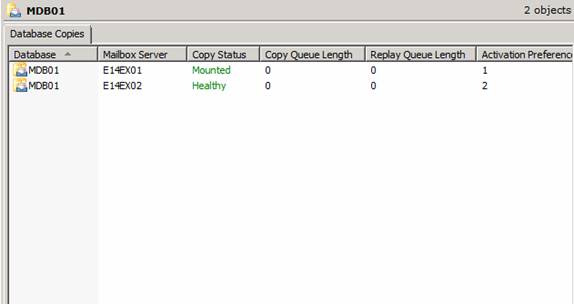
As you can see in the Exchange Management Console (Figure 27), we now have a healthy copy of the active database.
Figure 27: Healthy copy of active database
If we log on to the Mailbox server to which the database copy was added, we can also see that the database has been seeded (Figure 28) and the log files has been replicated (Figure 29).
Figure 28: Log files replicated to the Mailbox server holding the passive database copy
Figure 29: Database seeded to the other Mailbox server
Now perform the same steps for the other Mailbox database.
We have reached the end of part 3. In the next part we will have a look at how you re-seed databases, how database fail/switch-overs (*-overs) work and much more. See you then!
In the first part of this multi-part article uncovering Exchange 2010 Database Availability Groups (DAGs); we had a look at what Exchange 2007 and earlier versions provided when it comes to native high availability functionality for Mailbox servers.
In this part of this multi-part series, I will provide the steps necessary in order to prepare two servers to be used in a two DAG member solution. Both Exchange 2010 servers are placed in the same Active Directory site in the same datacenter. Multi-site DAG deployments will be uncovered in a separate article here on MSExchange.org in a future article, since this type of deployment includes many considerations and additional details. Also, even though these servers will be configured as multi-role Exchange 2010 servers, I will not uncover redundancy configuration for the Hub Transport and Client Access server roles. Redundancy for the Client Access server role and the new RPC Client Access service has already been covered in a previous articles series of mine (can be found here). Redundancy in regards to the Hub Transport server will be uncovered in a future article.
Test Environment
The lab environment used as the basis for this multi-part article consists of one Windows 2008 R2 domain controller, one Windows Server 2008 R2 file server (will be used as witness server), and 2 domain-joined Windows 2008 R2 Enterprise edition servers on which Exchange 2010 will be installed. We use the Enterprise edition because DAG requires the Enterprise edition. This is because like CCR and SCR, DAG still utilizes part of the Windows Failover Cluster component (heartbeat, file share witness, and cluster database). The Exchange 2010 Client Access, Hub Transport and Mailbox server roles will be installed on both of the Windows Server 2008 R2 servers. Furthermore, note that the Exchange 2010 DAG functionality itself is not dependent on Exchange 2010 Enterprise edition (only Windows Server 2008 R2 Enterprise edition). This means that you can use the standard edition of Exchange 2010 (or the evaluation version) if you are going to follow along in your own lab. The standard edition just limits you to a total of 5 databases (including active and passive copies) on each Exchange 2010 server.
Each Exchange 2010 server has 2 network cards installed, one connected to the production network and another connected to an isolated heartbeat/replication network. Although it’s a general rule of thumb to use at least two NICs in each DAG member (one for MAPI access and one or more for replication, seeding and heartbeat purposes), it is worth mentioning that Microsoft supports using a single NIC for both MAPI access, replication, seeding, and heartbeats. This is good to know for the small organizations that want to utilize DAG.
As one of my intentions with this articles series is to demonstrate the support for deploying DAGs in an incremental fashion (a method explained in more detail in part 1), I will not install the Windows Failover Cluster component on any of the servers prior to creating the DAG.
Configuring Network settings
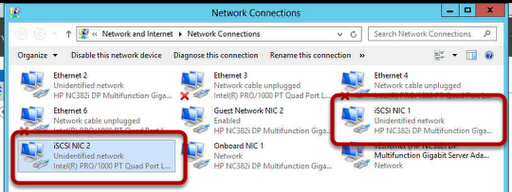
As already mentioned, two NICs have been installed in each server. Let us look at the way each NIC has been configured. To do so, open Network Connections. Here we have the NICs listed, and as you can see we have a PROD (connecting to the production network and providing MAPI connectivity) and a REPLICATION (connected to an isolated network) interface.
Figure 1: Network connections
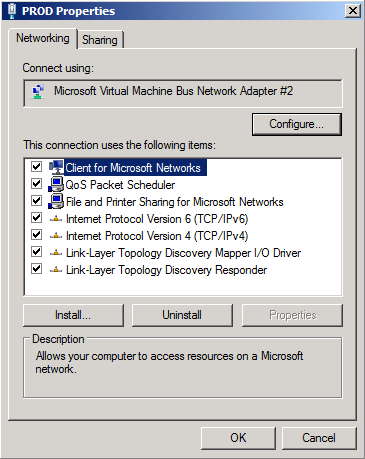
Let us first open the property page of the PROD interface. Here it is typically fine to leave the default settings as is. Optionally, you can uncheck QoS Packet Scheduler and Internet Protocol Version 6 (TCP/IP v6).
Figure 2: Properties of PROD interface
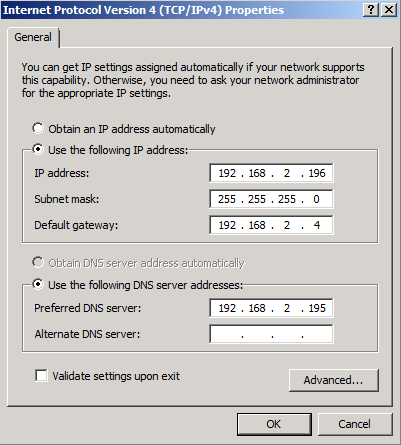
Open the property page of Internet Protocol Version 4 (TCP/IPv4). Here we have a static IP address configured as well as the other necessary settings (default gateway, subnet mask, and DNS server).
Figure 3: TCP/IP Version 4 Properties for the PROD interface
When you have configured the NIC correspondingly, close the property page by clicking OK twice.
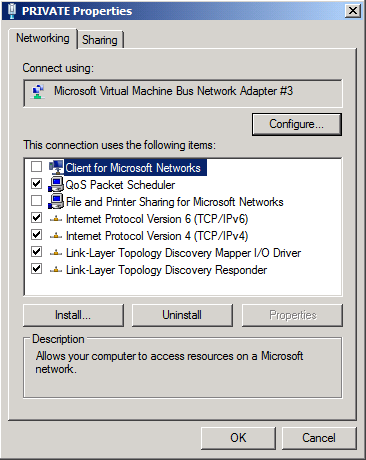
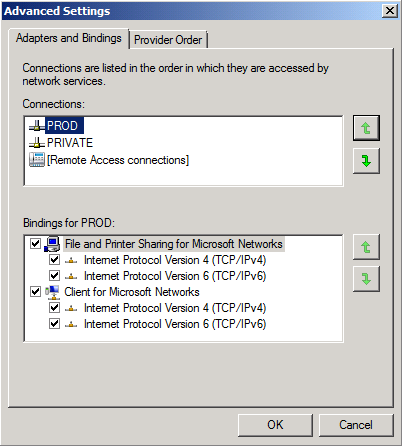
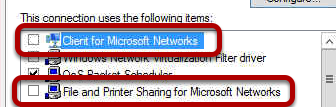
It’s time to configure the network settings for the “REPLICATION” interface, so let us open the property page of the “REPLICATION” NIC. Uncheck “Client for Microsoft Networks” and “File and Printer Sharing for Microsoft Networks” as shown in Figure 4. In addition, you may optionally uncheck QoS Packet Scheduler” and Internet Protocol Version 6 (TCP/IPv6).
Figure 4: Properties for the REPLICATION interface
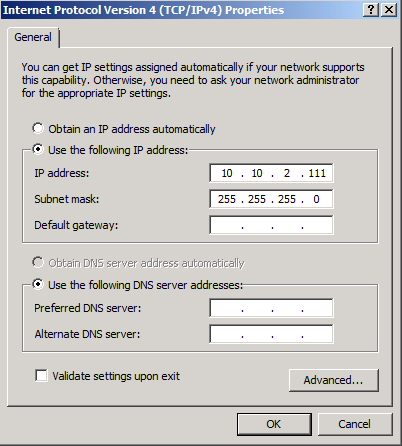
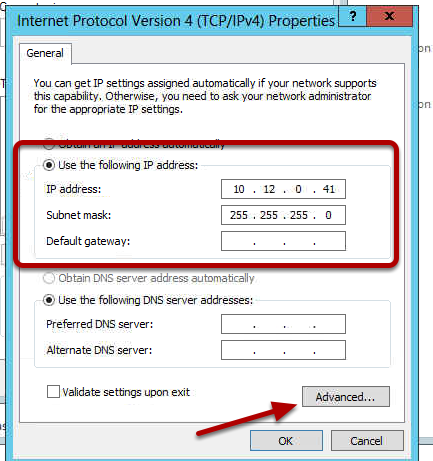
Now open property page of “Internet Protocol Version 4 (TCP/IPv4)” and enter an IP address and subnet mask on the isolated replication subnet. Since this NIC solely is used for replication, seeding and heartbeats, you should not specify any default gateway or DNS servers.
Note:
If routing on the “REPLICATION” interface for some reason is necessary between the two servers, you should use static routes instead of specifying a default gateway.
Figure 5: TCP/IP Version 4 properties for the REPLICATION interface
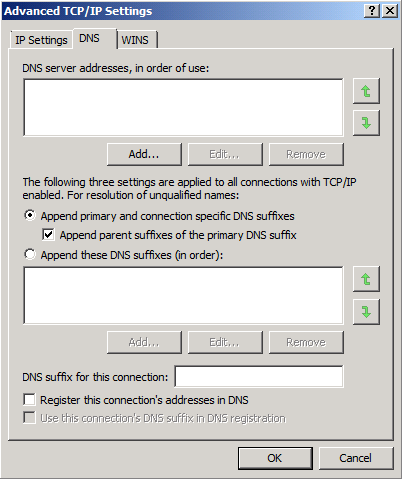
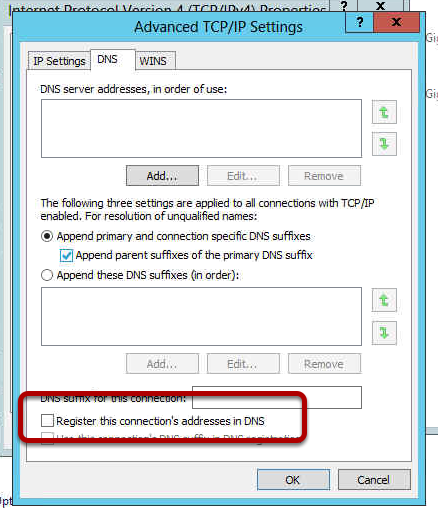
Now click “Advanced” and uncheck “Register this connection’s addresses in DNS” and then click “OK” twice.
Figure 6: Advanced TCP/IP Properties for REPLICATION interface
Now that we have configured each NIC, we must make sure the “PROD” NIC is listed first on the binding order list. To bring up the binding order list, you must press the ALT key, and then select Advanced > Advanced Settings.
Figure 7: Selecting Advanced Settings in the Network Connection menu
If not already the case, move the PROD NIC to the top as shown in Figure 8.
Figure 8: Binding order for the network interfaces
Click OK and close the Network Connections window.
Note:
You should of course make sure the above steps are performed on both servers.
Preparing Storage
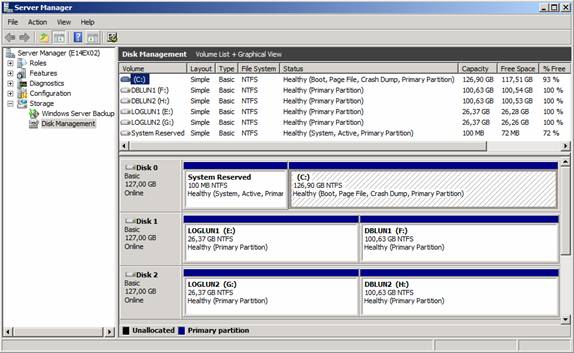
In the specific lab used in this article series, I have created a total four virtual disks (2x30GB for logs and 2×100 for active/passive database copies) for each server. To partition the disks used for mailbox databases and logs, open the Windows 2008 Server Manager and expand Storage and then select Disk Management. Now you should right-click on each LUN and then select Online in the context menu.
Assign each LUN (disk) identically on each server as shown in Figure 10 below.
Figure 9: LUNs (disk) on each lab server
Installing Exchange 2010 Server roles
Before we can install the Exchange 2010 Server roles on the two Windows 2008 R2 servers, we must first make sure the required features and components have been installed. The following components should be installed on all Exchange 2010 server roles:
NET-Framework
RSAT-ADDS
Web-Server
Web-Basic-Auth
Web-Windows-Auth
Web-Metabase
Web-Net-Ext
Web-Lgcy-Mgmt-Console
WAS-Process-Model
RSAT-Web-Server
Web-ISAPI-Ext
Web-Digest-Auth
Web-Dyn-Compression
NET-HTTP-Activation
RPC-Over-HTTP-Proxy
To install the above features, first open an elevated Windows PowerShell window and type:
Import-Module ServerManager
Figure 10: Importing the Server Manager module to Windows PowerShell
Then type the following command to installed the required features:
Figure 11: Installed required Windows Server 2008 R2 features
After the servers have rebooted, we must open an elevated Windows PowerShell window again, and set the service to start automatically. This can be accomplished with the following command:
Figure 12: Setting the NetTcpPortSharing feature to start automatically
Since we are going to install both the Hub Transport and Mailbox server role on these servers, we must also install theMicrosoft Filter Pack.
We’re now ready to install the Exchange 2010 roles on the servers. So mount the Exchange 2010 media and then run Setup. This brings us to the splash screen, where we should click on Step3: Choose Exchange language option so that we can install necessary languages on the servers.
Figure 13: Selecting Step 3: Choose Exchange language option
When step 3 has been completed, we can continue with Step 4: Install Microsoft Exchange.
Figure 14: Selecting Step 4: Install Microsoft Exchange
On the “Introduction” page, click Next.
Figure 15: Introduction page5
Accept the “License Agreement” and click Next.
Figure 16: License Agreement page
Select whether you want to enable “Error Reporting” or not, and then click Next.
Figure 17: Error Reporting page
Since we want to install Exchange 2010 server roles included in a typical installation, select this option and click Next.
Note:
Unlike Exchange 2007, you no longer specify whether you are installing a clustered mailbox server, since the DAG functioanlity is configured when you create a DAG after setup has completed.
Figure 18: Installation Type page
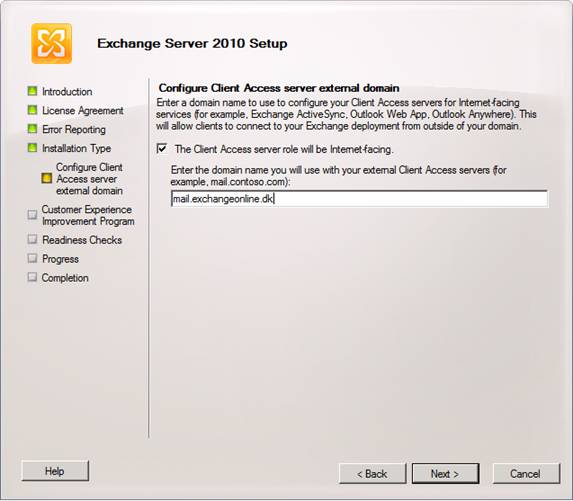
We will now face a new page that was not included in the Exchange 2007 Setup wizard. We have the option of specifiying whether this server will be Internet-facing. In large organizations (LORGs), you typically have one Internet-facing Active Directory site and all Client Access servers in this site should usually have this option enabled. Since both servers in our little lab will be Internet-facing, we will enable the option and specify the FQDN through which Exchange client services such as Outlook Web App (OWA), Exchange activeSync (EAS), and Outlook Anywhere will be will be accessed.
When you have done so, click Next.
Figure 19: Configuring Client Access server external domain
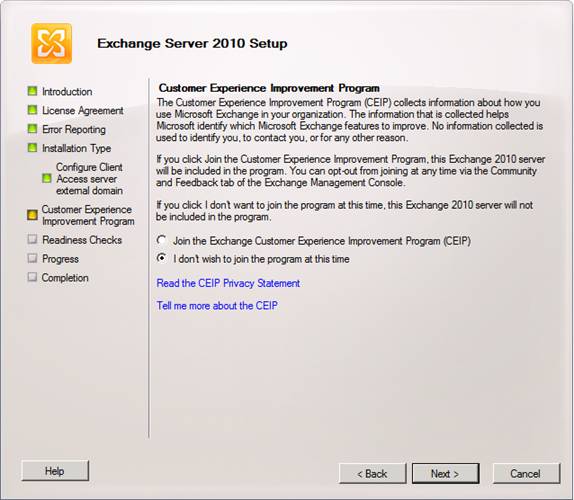
Now choose whether you want to participate in the customer experience improvement program or not, then click Next.
Note:
You must also install a subject alternative names (SAN) certificate in order to get client services working properly. However, this is outside the scope of this article series.
Figure 20: Customer Experience Improvement Program page
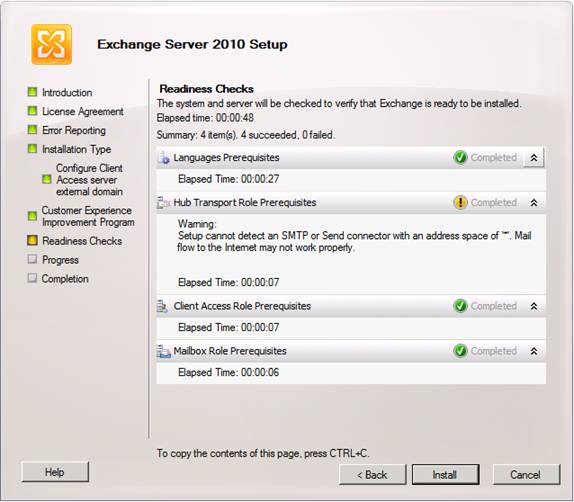
The readiness check will now begin, and hopefully you will not face any errors that will block you from proceeding. When possible, click Install.
Figure 21: Readiness Check page
The Exchange server roles are now being installed.
Figure 22: Installing Exchange 2010 server roles
When setup (hopefully) has completed successfully, click Finish.
Figure 23: Exchange 2010 Server roles installed successfully
That was all I had to share with you in part 2, but you can look forward to part 3 which will be published in the near future here on MSExchange.org. In part 3, I show you how to configure a WNLB to work with a Client Access array.
High Availability Changes in Exchange Server 2010?
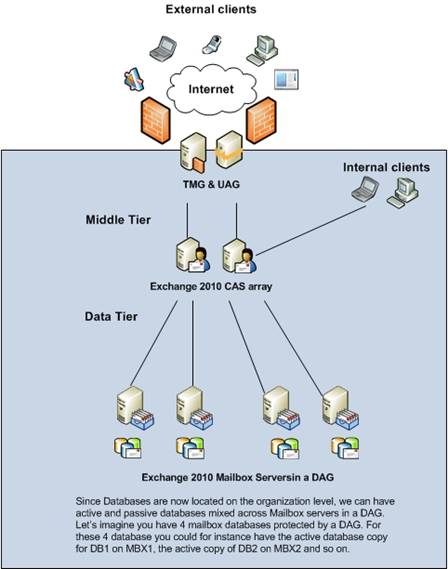
With Exchange 2010, we no longer have the concept of Local Continuous Replication (LCR), Single Copy Clusters (SCC), Cluster Continuous Replication (CCR) or Standby Continuous Replication (SCR) for that matter. WHAT!? I hear some of you yell! Yes I am not kidding here. But to be more specific, only LCR and SCC have been removed from the Exchange Server product. CCR and SCR have been combined and have evolved into a more unified high availability framework in which the new Database Availability Group (DAG) act as the base component. This means that no matter if you are going to deploy a local or site-level highly available or disaster recoverable solution, you use a DAG. To make myself clear, with Exchange 2010, your one and only method to protect mailbox databases is by using DAG.
Figure 1: Mailbox databases protected by DAG
The primary component in a DAG is a new component called Active Manager. Instead of the Exchange cluster resource DLL (exres.dll) and the associated cluster service resources that were required when clustering Exchange 2007 and previous versions of Exchange, Exchange 2010 now relies on the Active Manager to manage switch-overs and fail-overs (*-overs) between mailbox servers part of a DAG. Active Manager runs on all Mailbox servers in a given DAG. We have 2 active manager roles, the Primary Active Manager (PAM) and the Standby Active Manager (SAM). For a detailed explanation of the PAM and the SAM roles, please see the relevant Exchange 2010 Online documentation over at Microsoft TechNet.
So what’s interesting about a DAG then? Well there are many things; the most notable are listed in the following:
Limited dependency on Windows Failover Clustering – A DAG only uses a limited set of the clustering features provided by the Windows Failover Clustering component. DAG uses the cluster database, heartbeat, and file share witness functionality. With Exchange 2007 (and earlier versions), Exchange were an application operated by a Windows Failover Cluster. This is no longer the case with Exchange 2010. The Exchange cluster resource DLL (exres.dll) and all the cluster resources it created when it was registered have been removed from the Exchange 2010 code.
Figure 2: DAG still relies on cluster database, heartbeat and replication of the Windows Failover Cluster component
Figure 3: No Exchange Cluster Resources in the Windows Failover Cluster
Incremental deployment – Because DAGs still use some of the WFC components such as the cluster database, heartbeat and file share witness functionality, Windows Server 2008 SP2 or R2 Enterprise edition is required in order to be able to configure Exchange 2010 Mailbox servers in a DAG. But Exchange 2010 supports an incremental deployment approach meaning that you don’t need to form a cluster prior to installing Exchange 2010. You can install the Exchange 2010 Mailbox servers, and then create a DAG and add the servers and any databases to the DAG when needed.
Co-existence with other Exchange roles – With CCR you could not install other Exchange Server roles on the mailbox servers (cluster nodes) that were protected using CCR. With DAG, a mailbox server part of a DAG can have other Exchange roles installed. This is especially beneficial for small organizations. Because now that a DAG protected Mailbox server can co-exist with other Exchange roles, it also means that you can have a fully redundant Exchange 2010 solution with only two machines dedicated as Exchange servers. Of course, you need to configure a file share witness, but this could be any in your environment. The file share witness does not need to run the same Windows version as the Exchange 2010 servers. It just needs to run Windows server 2003 or later. Another thing you should bear in mind is that if you go down the path where you use two Exchange 2010 servers, and you want to have a fully redundant solution, you must use an external hardware or software based load balancing solution for Client Access services.
Managed 100% via Exchange tools – With CCR in Exchange 2007, you had to configure and manage CCR clusters using a combination of Exchange and cluster management tools. With DAGs in Exchange 2010, you no longer need to use cluster management tools for either the initial configuration or management. You can manage DAGs fully using the Exchange Management tools. This means that the Exchange administrators within an enterprise no longer need to have cluster experience (although this still could be a good idea).
Figure 4: DAG, replication networks, and FSW settings etc. managed via Exchange tools
Replication at the database level – In order to support the new DAG feature, databases in Exchange 2010 has now been moved to the organizational level instead of the server level where they existed in Exchange 2007 and earlier versions. This also means Exchange 2010 does not have the concept of storage groups any longer. Now there are databases and a log stream associated with each database. One drawback of CCR was that if only one database failed on the active node, a fail-over of all active databases existing on the clustered mailbox server were moved to the passive CCR node. This meant that all users on that had a mailbox stored on the respective CMS were affected.
Figure 5: Databases on the organization level
Support for up to 16 members in each DAG – Now that you can add up to 16 Mailbox servers to a DAG and potentially have 16 copies of each Mailbox database, Exchange 2010 had to support a larger number of mailbox databases than Exchange 2007 did. So the maximum limit has now been upped from 50 to 100 Mailbox database in the Exchange 2010 Enterprise edition. However, the Standard edition still only supports up to 5 databases per Mailbox server.
Switch/Fail-overs much quicker than in the past – Because of the improvement made with Exchange 2010 DAG, we will now experience much quicker switches and fail-overs (*-overs) between mailbox database copies. They will typically occur in under 30 seconds, compared to several minutes with CCR in Exchange 2007. In addition, because Outlook MAPI clients now connect to the RPC Client Access service on the Client Access Servers, end users will rarely notice a *-over occurred. You can read more about the RPC Client Access service in a previous articles series of minehere.
Go backup-less with +3 DB copies – When having 3 or more copies of a mailbox database, it is programmed to backup-less. This means that you basically enable circular logging on all mailbox databases protected by DAG, and no longer perform backups as we know them. This thinking of course requires enterprise organizations to change their mindset in regards to how they think mailbox databases should be protected.
Support for DAG members in separate AD sites – Unlike CCR cluster nodes, you can have DAG member servers located in different Active Directory sites. This should be a welcome addition to those of you who do not have the option of using the same AD site across physical locations (datacenters). It should be noted though, that you cannot place Mailbox servers protected by the same DAG in different domains within your Active Directory forest.
Log shipping via TCP – In Exchange 2007, the Microsoft Exchange Replication Service copied log files to the passive database copy (LCR), passive cluster node (CCR) or SCR target over Server Message Block (SMB), which meant you needed to open port 445 in any firewall between the CCR cluster nodes (typically when deploying multisite CCR clusters) and/or SCR source and targets. Those of you who work for or with a large enterprise organization know that convincing network administrators to open port 445/TCP between two datacenters is far from a trivial exercise. With Exchange 2010 DAG, the asynchronous replication technology no longer relies on SMB. Exchange 2010 uses TCP/IP for log file copying and seeding and, even better, it provides the option of specifying which port you want to use for log file replication. By default, DAG uses port 64327, but you can specify another port if required.
Log file compression – with Exchange 2010 DAGs you can enable compression for seeding and replication over one or more networks in a DAG. This is a property of the DAG itself, not a DAG network. The default setting is InterSubnetOnly and has the same settings available as those of the network encryption property.
Log file encryption – Exchange 2010 DAG supports the use of encryption whereas log files in Exchange 2007 are copied over an unencrypted channel (unless IPsec has been configured). More specifically, DAG leverages the encryption capabilities of Windows Server 2008—that is, DAG uses Kerberos authentication between each Mailbox server member of the respective DAG. Network encryption is a property of the DAG itself, not the DAG network. Settings for a DAG’s network encryption property are: Disabled (network encryption not in use), Enabled (network encryption enabled for seeding and replication on all networks existing in a DAG), InterSubnetOnly (the default setting meaning network encryption in use on DAG networks across subnets), and SeedOnly (network encryption in use for seeding on all networks in a DAG).
Up to 14 day lagged copies – With Standby Continuous Replication which were included in Exchange 2007 SP1, the concept of lagged database copies were introduced. With this feature we could delay the time for when log files that were copied to the SCR target should be replayed into the databases on the SCR target. We also had the option of specifying a so called truncation lag time, which was an option which allowed us to delay the time for when log files that had been copied to the SCR target and replayed into the cop of the database should be truncated. With both options we could specify a lag time of up to 7 days. With Exchange 2010 DAG, we can now specify a truncation lag time of up to 14 days, which is extra interesting when you choose to go backup-less.
Seeding from a DB copy – Unlike CCR in Exchange 2007, we can now perform a seed by specifying a database copy as the source database. This means that a new seed or a re-seed of an existing mailbox database no longer has any impact on the active database copy.
Figure 6: Seeding from a selective source server
Public folder databases not protected by DAG – Unlike CCR in Exchange 2007, we cannot protect public folder databases using DAG. Public folder databases must be protected using traditional public folder replication mechanisms. The positive thing about this is that we no longer are limited to only one public folder store in the Exchange organization, if it is stored on a DAG member server. With CCR we could only have one public folder store, when it was protected by CCR.
Improved Transport Dumpster – The transport dumpster we know from Exchange 2007 has also been improved, so that messages are re-delivered even when a lossy database failover occurs between databases copies stored in different Active Directory sites. In addition to this, when all messages have been replicated to all database copies, they will be deleted from the transport dumpster.
So with this part one of this multi-part article ends. In the next part, we will begin deploying DAG in our lab environment and look at the various DAG specific setting and so forth. Until then, have a nice one.
This is how to configure Multi Path I/O for iSCSI on Windows 2012 Server. I want to use this for our Hyper-V implementation to increase through put and redundancy.
Setup iSCSI NICs
In this server I have eight NICS, I have chosen to use two NICS for iSCSI and here you can see I have chosen to use one onboard Broadcom NIC and one PCI-e slot Intel NIC. Each NIC is configured with an IP address in the subnet of the storage network. In this case it is
10.12.0.40 255.255.255.0
10.12.0.41 255.255.255.0
The SAN is a HP MSA P2000 G3 iSCSI LFF and I have configured the Host NICS as
On each NIC you can remove services that are not required for iSCSI so I have unchecked Client for Microsoft Networks and File and Printer Sharing for Microsoft Networks.
Set IP Address
I will be using IP v4 for this implementation.
Confirm IP Address
Use static IP addresses to reduce need for DHCP and network overhead for that protocol. You do not need a gateway if the storage network is not to be routable. Each NIC needs to not use DNS to again improve performance so choose the Advanced option.
Do not register in DNS
Uncheck the option for Register this connections addresses in DNS. We do not want any IP from the iSCSI network in DNS.
Advanced NIC Settings
Each NIC has advanced settings and some relate to Power Management, we do not want any interruptions in the iSCSI network so we will change the advanced settings with the Configure option.
Power Management
Uncheck the option Allow the computer to turn off this device to save power.
Add MPIO Role
Now we will add the Multi Path Input Output (MPIO) role to the server so that we can use MPIO. From the Server Management dashboard choose the Manage Add Roles and Features option.
Add Features
Follow through the add roles and features and then at the Select Featuresoption choose Multipath I/O. In this example I have already installed this feature which is why the (Installed) is displayed. The server will now installt he MPIO feature.
MPIO Tools
Once the feature is installed you can then choose Tools MPIO from the Server Management Dashboard.
MPIO Properties – Immeadiate Reboot Required
In the MPIO dialog choose the Discover Multi-Paths tab and then check theAdd support for iSCSI devices option. The server will now require an immeadiate reboot so be prepared.
iSCSI Initiator
Now the server has rebooted we are ready to setup iSCSI, this is done from the Server Management and Tools, iSCSI Initiator.
Connecting to a Target
iSCSI works be connecting to a Target, the target is most likely a disk SAN or similar, in our case it is the HP MSA P2000 G3 iSCSI SAN. A target is an IP address that is configured on the iSCSI port on the SAN. 10.12.0.20 is the first IP address assigned to my Controller A iSCSI A1 port so I choose the Quick Connect option.
Quick Connect
The quick connect will now communicate to the SAN using the iSCSI NIC on the server and the iSCSI port on the SAN. It negotiates and we see under the Discovered Targets section the IQN of the SAN. You can see in the IQN name the hp:storage.p2000 text, this is part of the IQN name of our SAN. You can check this information on your iSCSI Storage Device as these will be different across manufacturers. Click Done to return to the iSCSI Initiator.
Add the first Multi Path
Select the target and then click on Properties to add the next path to the iSCSI Storage Device.
Sessions
This dialog will show the existing sessions to the iSCSI Storage Device, we have only added one session so far so we will only have one path to the iSCSI Storage Device and if we removed the network cable for the iSCSI NIC we would lose connection to the target. What we want is to be able to lose one connection and know that the second iSCSI NIC can carry on the iSCSI traffic. So choose Add Session to add the second iSCSI session.
Connect to Target
When you add the new session you are asked do you want to use Multi Path,, check the Enable Multi-Path option and then choose the Advancedoption.
Advanced Settings
In this dialog we are going to choose which type of adapter we are going to use, as we have no Hardware Based Adapters (HBA) we will use theMicrosoft iSCSI Initator which is software based so select this from the Local Adapter dropdown.
Intiator IP
From the Initiator IP dropdown choose the IP Address you have assigned to the second iSCSI NIC, in this case this is the IP address 10.12.0.40. This will now connect the second iSCSI NIC to our target so that both iSCSI NICS can communicate with the iSCSI Storage Device. Choose OK.
Confirm MPIO for each Session
A session will now be created with a long GUID, check the new session and then click on the Devices button to see what devices are connected in this session. We are looking to see two devices, one for each of the iSCSI Target IP addresses.
Devices
I recommend that you create a LUN on your iSCSI Storage Device in advance as you then have a device to see as connected, here I can see the disk I have created on LUN 0. I now choose the MPIO button.
Device Details
This displays the MPIO details and the Load Balance Policy. This is the way that the MPIO trys to communicate with the iSCSI Target, we would like it toRound Robin. This means that the first IP address is sent a packet and then the next and so on until the packets come round to the start again. The benefit here is that all paths get used and you can have multiple packets sent at once so you get better performance. If a path is down due to a cable failure or swich failure the round robin notices this and ignore the path and sends the packet on the next active path. So you have a high performance and redundant iSCSI infrastructure.
To see the IP addresses used for a path, click on a path and then choose the Details button.
MPIO Details
In the details of the path you can see the Source and Target IP address details. Here we can see the Source is the iSCSI NIC on the server 10.12.0.41 and the target is the IP address of Controller A iSCSI A1 port 10.12.0.20.
MPIO Details on second path
On the second path you can see the Source is now the other iSCSI NIC on the Server and the Target is the Controller A iSCSI A1 port so we have two paths now to this target.
Confirm the MPIO
You can confirm the MPIO in use with a command line tool calledmpclaim. Here I have ran the command mpclaim -v c:config.txt This will output the MPIO configuration in verbose mode to a text file so it is easy to read.
Text File Output
I open the Config.txt file and I can see the MPIO states we have 2 Paths so I know the paths I have created are live. So all I need now is to go do this all again for each target IP addresss on my iSCSI Storage Device to built the multiple paths.